Apache Kafka 是一个开源事件流平台,用于实时大规模收集、处理、存储和集成数据。它支持多种用例,包括流处理、数据集成和发布/订阅消息传递。
Kafka 最初由 LinkedIn 开发,于 2011 年开源,并于 2012 年成为 Apache 软件基金会项目。全球数千家组织使用它来支持关键任务实时应用程序,包括证券交易所、电子商务应用程序、物联网监控和分析等等。
有本叫《Kafka权威指南》 第2版,不过我也没看过,😄。
看什么书,不如看官方文档 https://kafka.apache.org/documentation ,把基础的东西掌握好,再看其他相关的书籍增强理论知识。学会基本概念后,一定要去看官方文档,增强自己。自上而下,先从整体简单内容入手,再细读文档。
Getting Started
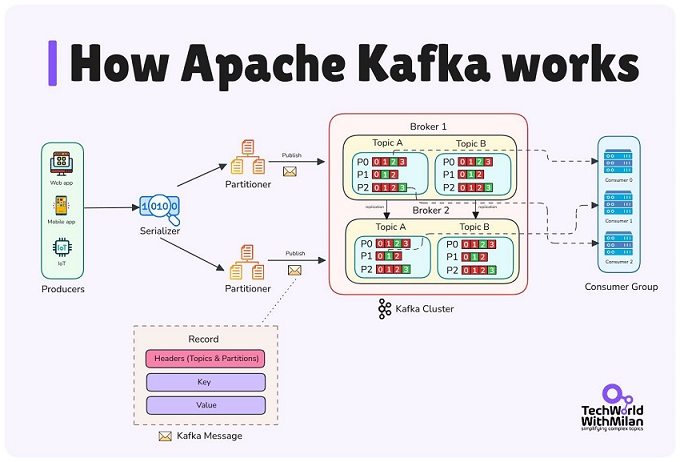
How Apache Kafka works.
Introduction
从技术角度来说,事件流处理是指以事件流的形式从数据库、传感器、移动设备、云服务和软件应用程序等事件源实时捕获数据;持久存储这些事件流以供日后检索;实时和回顾性地操作、处理和响应事件流;并根据需要将事件流路由到不同的目标技术。因此,事件流处理可确保数据的连续流动和解读,从而确保正确的信息在正确的时间出现在正确的位置。
Kafka 结合了三种关键功能:
所有这些功能都以分布式、高度可扩展、弹性、容错且安全的方式提供。Kafka 可以部署在裸机硬件、虚拟机和容器上,也可以部署在本地和云端。您可以选择自行管理 Kafka 环境,也可以使用由多家供应商提供的完全托管服务。
Kafka是一个分布式系统,由服务器和客户端组成,之间用TCP通信;
服务器:Kafka 由一台或多台服务器组成的集群运行,这些服务器可以跨越多个数据中心或云区域。其中一些服务器构成存储层,称为 代理 (broker)。其他服务器运行 Kafka Connect,以事件流的形式持续导入和导出数据,从而将 Kafka 与您现有的系统(例如关系数据库)以及其他 Kafka 集群集成。为了帮助您实现关键任务用例,Kafka 集群具有高度的可扩展性和容错能力:如果其中任何一台服务器发生故障,其他服务器将接管其工作,以确保持续运行且不会丢失任何数据。
客户端:允许您编写分布式应用程序和微服务,以便能够并行、大规模地读取、写入和处理事件流,即使在网络问题或机器故障的情况下也能保持容错能力。
向 Kafka 读取或写入数据时,您是以事件的形式进行的,如:
生产者是向Kafka发布(写入)事件地客户端应用程序,而消费者是订阅(读取和处理)这些事件地应用程序。在 Kafka 中,生产者和消费者完全解耦,彼此互不影响,这是 Kafka 实现其高可扩展性的关键设计元素。例如,生产者无需等待消费者。Kafka 提供了各种保证,例如 “恰好一次” 处理事件的能力。
事件被组织并持久存储在主题(Topic)中,主题类似于文件系统中地文件夹,事件就是该文件夹中的文件。
Kafka 中的主题始终是多生产者和多订阅者的:一个主题可以有零个、一个或多个向其写入事件的生产者,以及零个、一个或多个订阅这些事件的消费者。
主题中的事件可以根据需要随时读取——与传统消息传递系统不同,事件在消费后不会被删除。
相反,您可以通过每个主题的配置设置来定义 Kafka 应保留事件的时间,超过此时间后,旧事件将被丢弃。Kafka 的性能相对于数据大小而言实际上是恒定的,因此长期存储数据完全没问题。
主题(Topic)是分区的,一个主题会分布在位于不同Kafka代理Broker上的多个“存储桶”中。
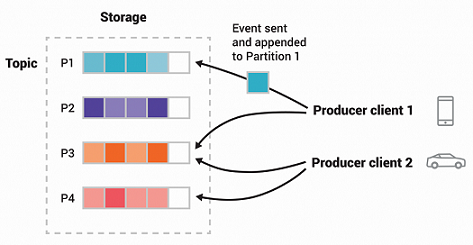
为了确保数据容错性和高可用性,每个主题都可以进行复制,甚至可以跨地理区域和数据中心进行复制。这样,在出现问题、需要对代理进行维护等情况下,始终有多个代理拥有数据副本。常见的生产环境设置是复制因子为 3,即始终有三个数据副本。
除了用于管理任务的命令行工具外,Kafka 还有五个核心 API:
Use Cases
Kafka 能有效替代传统消息代理(如 ActiveMQ、RabbitMQ),其高吞吐量、内置分区、复制和容错功能远超大多数系统。消息代理常用于解耦生产者与处理过程、缓冲消息等,是大规模消息处理应用的理想方案。
Kafka 最初用于重建用户活动跟踪管道为实时发布-订阅数据流:网站活动(如页面浏览、搜索)发布到对应主题,可订阅用于实时处理、监控,或加载到 Hadoop/数据仓库进行离线分析。活动数据量巨大,每页浏览生成多条消息。
Kafka 常用于操作监控数据。这涉及聚合来自分布式应用程序的统计数据,以生成集中式的操作数据。
Kafka 常替代日志聚合方案,后者从服务器收集物理日志文件并集中存储(如 HDFS)处理。Kafka 将日志/事件抽象为消息流,降低延迟,支持多数据源和分布式消费。相较 Scribe/Flume 等系统,Kafka 性能相当,但提供更强复制持久性和更低端到端延迟。
许多 Kafka 用户通过多阶段处理管道处理数据:原始输入从 Kafka 主题消费,经聚合、丰富或转换后发布到新主题,用于进一步消费。例如,新闻推荐管道:RSS 抓取文章到“文章”主题;规范化/去重后发布到新主题;最终推荐给用户,形成实时数据流图。从 0.10.0.0 版本起,Kafka 提供轻量级流处理库 Kafka Streams 执行此类操作;其他开源工具包括 Apache Storm 和 Apache Samza。
事件溯源是一种应用程序设计风格,其中状态变化以按时间顺序排列的记录序列进行记录。Kafka 支持存储海量日志数据,使其成为此类应用程序的理想后端。
Kafka 可作为分布式系统的外部提交日志,用于节点间数据复制和故障节点恢复的重新同步;其日志压缩功能支持此用法,类似于 Apache BookKeeper。
Quick Start
哪些手动部署的搭建环境的方式我们直接跳过,我们直接用 docker-compose
拉取Docker镜像
root@ser745692301841:/dev_dir/note# docker pull apache/kafka:4.1.0
root@ser745692301841:/dev_dir/note# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
apache/kafka 4.1.0 a183a690a3a6 7 weeks ago 437MBhttps://hub.docker.com/r/apache/kafka 仓库中的概述中 对于怎么使用写得很清楚。直接部署多节点的集群。
该部署由3个Broker和3个Controller组成,它们分别在各自的容器中运行(即KRaft隔离模式)。在Docker中进行此练习可以方便地了解多Broker配置和Kafka协议, 但此Docker Compose示例不适用于生产部署。
kafka/docker-compose.yml
services:
controller-1:
image: apache/kafka:4.1.0
container_name: controller-1
environment:
KAFKA_NODE_ID: 1
KAFKA_PROCESS_ROLES: controller
KAFKA_LISTENERS: CONTROLLER://:9093
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@controller-1:9093,2@controller-2:9093,3@controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
controller-2:
image: apache/kafka:4.1.0
container_name: controller-2
environment:
KAFKA_NODE_ID: 2
KAFKA_PROCESS_ROLES: controller
KAFKA_LISTENERS: CONTROLLER://:9093
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@controller-1:9093,2@controller-2:9093,3@controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
controller-3:
image: apache/kafka:4.1.0
container_name: controller-3
environment:
KAFKA_NODE_ID: 3
KAFKA_PROCESS_ROLES: controller
KAFKA_LISTENERS: CONTROLLER://:9093
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@controller-1:9093,2@controller-2:9093,3@controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
broker-1:
image: apache/kafka:4.1.0
container_name: broker-1
ports:
- 29092:9092
environment:
KAFKA_NODE_ID: 4
KAFKA_PROCESS_ROLES: broker
KAFKA_LISTENERS: 'PLAINTEXT://:19092,PLAINTEXT_HOST://:9092'
KAFKA_ADVERTISED_LISTENERS: 'PLAINTEXT://broker-1:19092,PLAINTEXT_HOST://127.0.0.1:29092'
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@controller-1:9093,2@controller-2:9093,3@controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
depends_on:
- controller-1
- controller-2
- controller-3
broker-2:
image: apache/kafka:4.1.0
container_name: broker-2
ports:
- 39092:9092
environment:
KAFKA_NODE_ID: 5
KAFKA_PROCESS_ROLES: broker
KAFKA_LISTENERS: 'PLAINTEXT://:19092,PLAINTEXT_HOST://:9092'
KAFKA_ADVERTISED_LISTENERS: 'PLAINTEXT://broker-2:19092,PLAINTEXT_HOST://127.0.0.1:39092'
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@controller-1:9093,2@controller-2:9093,3@controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
depends_on:
- controller-1
- controller-2
- controller-3
broker-3:
image: apache/kafka:4.1.0
container_name: broker-3
ports:
- 49092:9092
environment:
KAFKA_NODE_ID: 6
KAFKA_PROCESS_ROLES: broker
KAFKA_LISTENERS: 'PLAINTEXT://:19092,PLAINTEXT_HOST://:9092'
KAFKA_ADVERTISED_LISTENERS: 'PLAINTEXT://broker-3:19092,PLAINTEXT_HOST://127.0.0.1:49092'
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@controller-1:9093,2@controller-2:9093,3@controller-3:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
depends_on:
- controller-1
- controller-2
- controller-3Kafka3.0+版本引入地角色分离模式,将控制器和代理分离运行,控制器专注于控制平面,broker 专注于数据平面。整个集群总共 6 个节点(Node ID 从 1 到 6):
控制器节点(controller-1、controller-2、controller-3)
这三个服务是专用控制器,每个运行一个Kafka进程,但仅扮演controller角色,它们形成一个3节点quorum,确保高可用(至少2个节点存活即可维持集群)
image: apache/kafka:4.1.0:使用官方 Kafka Docker
镜像。container_name:容器命名,便于管理(如
controller-1)。KAFKA_PROCESS_ROLES: controller:指定进程仅作为控制器运行,不处理
broker 职责。KAFKA_LISTENERS: CONTROLLER://:9093:监听控制器端口
9093,用于内部 quorum 通信。KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT:内部
broker 通信使用 PLAINTEXT 协议(无加密)。KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER:定义控制器监听器的名称。KAFKA_CONTROLLER_QUORUM_VOTERS: 1@controller-1:9093,2@controller-2:9093,3@controller-3:9093:定义
quorum 投票成员列表。格式为
<node_id>@<hostname>:<port>,所有控制器互相投票选举元数据领导者。KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0:消费者组再平衡初始延迟设为
0ms,加速测试环境启动(生产环境可调整)。代理节点(broker-1、broker-2、broker-3)
这三个服务是专用代理,每个运行一个Kafka进程,扮演broker角色,它们连接到控制器 quorum,处理消息生产/消费。
image: apache/kafka:4.1.0:同上。container_name:容器命名(如 broker-1)。ports: - <host_port>:9092:将容器内 9092
端口映射到主机(29092、39092、49092),允许外部客户端(如 Kafka
工具)连接。注意:主机端口不同,避免冲突。KAFKA_PROCESS_ROLES: broker:指定进程仅作为 broker
运行,不处理控制器职责。KAFKA_NODE_ID:唯一 ID(4、5、6)。KAFKA_LISTENERS: 'PLAINTEXT://:19092,PLAINTEXT_HOST://:9092':定义两个监听器:PLAINTEXT://:19092:内部监听器,用于
broker
间通信(容器网络内)。PLAINTEXT_HOST://:9092:外部监听器,用于主机连接。KAFKA_ADVERTISED_LISTENERS: 'PLAINTEXT://broker-<n>:19092,PLAINTEXT_HOST://localhost:<host_port>':广告监听器,告诉客户端如何连接。内部用容器名(broker-1
等),外部用 localhost:<host_port>。KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT:broker
间通信使用内部 PLAINTEXT 监听器(19092)。KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER:broker
连接控制器的监听器名称(尽管 broker
不运行控制器,但需声明以支持未来扩展)。KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT:映射监听器名称到协议(全
PLAINTEXT,无安全)。KAFKA_CONTROLLER_QUORUM_VOTERS:同控制器,broker 需知道
quorum 地址以注册集群。KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0:同上。depends_on: - controller-1 - controller-2 - controller-3:确保
broker 在所有控制器启动后才启动,避免连接失败。整体架构与注意事项
启动集群
oot@ser745692301841:/dev_dir/kafka# ls
docker-compose.yml
root@ser745692301841:/dev_dir/kafka# docker-compose up -d
Creating controller-2 ... done
Creating controller-1 ... done
Creating controller-3 ... done
Creating broker-2 ... done
Creating broker-1 ... done
Creating broker-3 ... done
root@ser745692301841:/dev_dir/kafka# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
0956bdcbb17f apache/kafka:4.1.0 "/__cacert_entrypoin…" 5 seconds ago Up 4 seconds 0.0.0.0:49092->9092/tcp broker-3
8e4c92bfc02f apache/kafka:4.1.0 "/__cacert_entrypoin…" 5 seconds ago Up 4 seconds 0.0.0.0:29092->9092/tcp broker-1
4c4d32f110c9 apache/kafka:4.1.0 "/__cacert_entrypoin…" 5 seconds ago Up 4 seconds 0.0.0.0:39092->9092/tcp broker-2
ec7e79ab7a37 apache/kafka:4.1.0 "/__cacert_entrypoin…" 5 seconds ago Up 5 seconds 9092/tcp controller-3
350c0ba616b7 apache/kafka:4.1.0 "/__cacert_entrypoin…" 5 seconds ago Up 5 seconds 9092/tcp controller-1
8842b034516f apache/kafka:4.1.0 "/__cacert_entrypoin…" 5 seconds ago Up 5 seconds 9092/tcp controller-2关闭集群
root@ser745692301841:/dev_dir/kafka# docker-compose down -v
Stopping broker-3 ... done
Stopping broker-1 ... done
Stopping broker-2 ... done
Stopping controller-3 ... done
Stopping controller-1 ... done
Stopping controller-2 ... done
Removing broker-3 ... done
Removing broker-1 ... done
Removing broker-2 ... done
Removing controller-3 ... done
Removing controller-1 ... done
Removing controller-2 ... done
Removing network kafka_default
root@ser745692301841:/dev_dir/kafka# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES进入一个broker
root@ser745692301841:/dev_dir/kafka# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
d08c34dd951f apache/kafka:4.1.0 "/__cacert_entrypoin…" 18 seconds ago Up 17 seconds 0.0.0.0:39092->9092/tcp broker-2
66fd553b04b4 apache/kafka:4.1.0 "/__cacert_entrypoin…" 18 seconds ago Up 17 seconds 0.0.0.0:29092->9092/tcp broker-1
3e416ba03096 apache/kafka:4.1.0 "/__cacert_entrypoin…" 18 seconds ago Up 17 seconds 0.0.0.0:49092->9092/tcp broker-3
7edffc89670e apache/kafka:4.1.0 "/__cacert_entrypoin…" 19 seconds ago Up 18 seconds 9092/tcp controller-3
4aea596b68c7 apache/kafka:4.1.0 "/__cacert_entrypoin…" 19 seconds ago Up 18 seconds 9092/tcp controller-2
d15a99927a5b apache/kafka:4.1.0 "/__cacert_entrypoin…" 19 seconds ago Up 18 seconds 9092/tcp controller-1
root@ser745692301841:/dev_dir/kafka# docker exec --workdir /opt/kafka/bin/ -it broker-1 sh
/opt/kafka/bin $ ls
connect-distributed.sh kafka-client-metrics.sh kafka-consumer-groups.sh kafka-features.sh kafka-metadata-quorum.sh kafka-server-start.sh kafka-streams-groups.sh trogdor.sh
connect-mirror-maker.sh kafka-cluster.sh kafka-consumer-perf-test.sh kafka-get-offsets.sh kafka-metadata-shell.sh kafka-server-stop.sh kafka-topics.sh windows
connect-plugin-path.sh kafka-configs.sh kafka-delegation-tokens.sh kafka-groups.sh kafka-producer-perf-test.sh kafka-share-consumer-perf-test.sh kafka-transactions.sh
connect-standalone.sh kafka-console-consumer.sh kafka-delete-records.sh kafka-jmx.sh kafka-reassign-partitions.sh kafka-share-groups.sh kafka-verifiable-consumer.sh
kafka-acls.sh kafka-console-producer.sh kafka-dump-log.sh kafka-leader-election.sh kafka-replica-verification.sh kafka-storage.sh kafka-verifiable-producer.sh
kafka-broker-api-versions.sh kafka-console-share-consumer.sh kafka-e2e-latency.sh kafka-log-dirs.sh kafka-run-class.sh kafka-streams-application-reset.sh kafka-verifiable-share-consumer.sh生产消费测试
创建topic
/opt/kafka/bin $ ./kafka-topics.sh --bootstrap-server broker-1:19092,broker-2:19092,broker-3:19092 --create --topic test-topic
Created topic test-topic.开始消费
/opt/kafka/bin $ ./kafka-console-consumer.sh --bootstrap-server broker-1:19092,broker-2:19092,broker-3:19092 --topic test-topic --from-beginning再打开一个终端
./kafka-console-producer.sh --bootstrap-server broker-1:19092,broker-2:19092,broker-3:19092 --topic test-topic在producer终端敲的内容,会被consumer终端消费到。
# producer终端
root@ser745692301841:/dev_dir/kafka# docker exec --workdir /opt/kafka/bin/ -it broker-1 sh
/opt/kafka/bin $ ./kafka-console-producer.sh --bootstrap-server broker-1:19092,broker-2:19092,broker-3:1909
2 --topic test-topic
>
>nihao
>hello world
>^C/opt/kafka/bin $
# consumer终端
/opt/kafka/bin $ ./kafka-console-consumer.sh --bootstrap-server broker-1:19092,broker-2:19092,broker-3:19092 --topic test-topic --from-beginning
nihao
hello world如果重新 执行 kafka-console-consumer.sh test-topic
--from-beginning 将会看到 nihao、hello world
又被消费一遍,这是因为--from-beginning的原因,从头开始消费流内容。
主机硬件资源有限,我们可以用 一个 controller、一个broker
services:
controller-1:
image: apache/kafka:4.1.0
container_name: controller-1
environment:
KAFKA_NODE_ID: 1
KAFKA_PROCESS_ROLES: controller
KAFKA_LISTENERS: CONTROLLER://:9093
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@controller-1:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
broker-1:
image: apache/kafka:4.1.0
container_name: broker-1
ports:
- 29092:9092
environment:
KAFKA_NODE_ID: 4
KAFKA_PROCESS_ROLES: broker
KAFKA_LISTENERS: 'PLAINTEXT://:19092,PLAINTEXT_HOST://:9092'
KAFKA_ADVERTISED_LISTENERS: 'PLAINTEXT://broker-1:19092,PLAINTEXT_HOST://localhost:29092'
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@controller-1:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
depends_on:
- controller-1Ecosystem
除了主发行版之外,还有大量工具可以与 Kafka 集成。生态系统页面 https://cwiki.apache.org/confluence/x/Ri3VAQ 列出了其中许多工具,包括流处理系统、Hadoop 集成、监控和部署工具。
Upgrading
一些漏洞,以及版本之间的重大更新,与问题修复,详细内容去看官方文档。
KRaft vs ZooKeeper
ZooKeeper 模式和 KRaft 模式之间存在许多差异。KRaft模式与 ZooKeeper 模式之间的差异页面列出了所有这些差异,包括配置、指标和行为变化。
https://kafka.apache.org/41/documentation/zk2kraft.html
不过入门学习,还没到不学这里不行,建议直接跳过,不要在此钻牛角尖。
Compatibility
Kafka 4.0 的发布引入了重大变更,影响了各个组件之间的兼容性。为了帮助用户规划升级并确保无缝互操作性, 我们准备了 一个全面的 兼容性矩阵 https://kafka.apache.org/41/documentation/compatibility.html。
4.0 是一个重要里程碑,建议直接从 4.0 以上开始学习。
Docker
我们在 快速学习 Docker Compose搭建Kafka集群环境 部分已经有了些了解。
APIS
Kafka包含5个核心API:
我喜欢node.js,所以用kafkajs来学习。
生产者API(Producer API)、消费者API(Consumer API)、分享消费者API Share Consumer API(Preview)、流API(Streams API)、连接API(Connect API)、管理API(Admin API)
Configuration,在Kafka的官方文档中,整个文档界面内容的接近一半都是 “配置”部分的文档内容。这东西我们根本没法记住,只能多了解,在实践中了解些Kafka的一些特性 调优等等。
Kafka支持提供了调整配置的方式给用户,但不一定需要用到大部分都是默认参数即可,只有我们需要定制化的时候再看这些配置内容也不迟。
Design
Motivation
我们设计 Kafka 的目的是让它成为一个统一的平台,处理大型公司可能拥有的 所有实时数据。为了实现这一点,我们必须考虑一系列相当广泛的用例。
它必须具有高吞吐量来支持大量事件流,例如实时日志聚合。
它需要妥善处理大量数据积压,以便能够支持来自离线系统的定期数据加载。
这也意味着系统必须处理低延迟传递才能处理更传统的消息传递用例。
我们希望支持对这些数据流进行分区、分布式、实时处理,从而创建新的派生数据流。这催生了我们的分区和消费者模型。
最后,在将流输入到其他数据系统进行服务的情况下,我们知道系统必须能够在机器故障时保证容错能力。
为了支持这些用途,我们设计了一个包含许多独特元素的系统,它更类似于数据库日志,而非传统的消息系统。
Persistence
Don’t fear the filesystem!, Kafka严重依赖文件系统来存储和缓存消息,人们普遍认为“磁盘很慢”,不要害怕,它可能比你想得块,没有你想得那么慢。
这段话的核心思想可以一句话概括为:
👉 别害怕用文件系统,顺序写 + OS 缓存比你想象的快。
简要总结如下:
Constant Time Suffices.
Kafka 为什么不用复杂的数据结构(比如 BTree),而是选择简单的顺序写文件的设计。下面是通俗总结👇
传统消息系统的做法
O(log N),听起来不错,但对磁盘来说其实很慢。为什么 BTree 慢?
log N 要慢得多。Kafka 的思路:O(1) 就够了
带来的好处
Kafka 的高性能来自于:
👉 “不玩花活”——不用复杂的 BTree、索引或事务系统,而是直接顺序写文件,让所有操作都接近常数时间,从而既快又省钱。
Efficiency
这段主要讲 Kafka 为什么这么快,精简总结如下👇
批量传输(Batching)
零拷贝(Zero-copy)
sendfile
系统调用,让操作系统直接从文件缓存(page
cache)发到网卡,不经过用户态。效果
sendfile,效率会稍低。Kafka 靠 批量发送 + 零拷贝传输,把磁盘和网络效率压榨到极致,实现了超高吞吐量。
The Producer
Kafka Producer(生产者) 的工作方式
Kafka Producer 通过 智能分区 + 异步批量发送 实现高效、可控的消息分发。
The Consumer
Kafka 消费者通过向其想要消费的分区所在的 Broker 发出“fetch”请求来工作。消费者在每次请求中指定其在日志中的偏移量,并从该位置开始接收一个日志块。因此,消费者对该位置拥有强大的控制权,并且可以根据需要回退该位置以重新消费数据。
Push vs. pull
为什么选择 消费者从Broker拉的方式,如果消费者消费速度较低,Broker一直推其实本质上成了一种拒绝服务攻击。拉取模式,Broker没数据消费者就进入了一种死循环,实际上就是忙着等待数据到达。为了避免这种情况,我们在拉取请求中设置了一些参数,允许消费者请求阻塞在“长轮询”中,直到数据到达。
Consumer Position
令人惊讶的是, 跟踪已消费的内容是消息传递系统的关键性能点之一。 大多数消息系统都会在 Broker 上保存已消费消息的元数据。也就是说,当消息被分发给消费者时,Broker 要么立即在本地记录该消息,要么等待消费者的确认。这是一个相当直观的选择,而且对于单机服务器来说,并不清楚这些状态还能保存在哪里。由于许多消息系统用于存储的数据结构扩展性较差,因此这也是一个务实的选择——由于 Broker 知道哪些消息已被消费,它可以立即删除,从而保持较小的数据大小。
或许不太明显的是,让 Broker 和 Consumer 就已消费的内容达成一致并非易事。如果 Broker 每次通过网络发送消息时都立即将其记录为 已消费,那么如果 Consumer 未能处理该消息(例如由于崩溃、请求超时或其他原因),该消息就会丢失。为了解决这个问题,许多消息系统添加了确认功能,这意味着消息在发送时仅被标记为 已发送,而不是 已消费;Broker 等待 Consumer 的特定确认,然后才将消息记录为 已消费。这种策略解决了消息丢失的问题,但也带来了新的问题。首先,如果 Consumer 处理了消息但在发送确认之前失败,那么该消息将被消费两次。第二个问题与性能有关,现在 Broker 必须为每条消息保留多个状态(首先锁定消息以防止再次发出,然后将其标记为永久消费以便将其删除)。必须处理一些棘手的问题,例如如何处理已发送但从未确认的消息。
Kafka 对此的处理方式有所不同。我们的主题被划分为一组完全有序的分区,每个分区在任何给定时间都只能被订阅消费者组中的一位消费者消费。这意味着消费者在每个分区中的位置只是一个整数,即下一条待消费消息的偏移量。这使得已消费消息的状态信息非常小,每个分区只有一个数字。此状态可以定期进行检查点。这使得消息确认的等效操作非常便宜。
这种做法还有一个附带好处。消费者可以故意回退到旧的偏移量并重新消费数据。这违反了队列的通用约定,但对许多消费者来说却是一项必不可少的功能。例如,如果消费者代码中存在 bug,并且在消费某些消息后才被发现,那么消费者可以在 bug 修复后重新消费这些消息。
Offline Data Load
可扩展的持久性允许消费者仅定期消费,例如批量数据加载,定期将数据批量加载到离线系统(如 Hadoop 或关系数据仓库)中。
Static Membership
这段话讲的是 Kafka 的「静态成员(Static Membership)」机制,下面是通俗易懂的总结👇
🧩 背景问题
在旧版本 Kafka 里,消费者组(Consumer Group)成员的身份是“临时的”:
💡 静态成员(Static Membership)的作用
为了解决上面的问题,Kafka 引入了 静态成员机制:
⚙️ 使用方法
Kafka 版本需 ≥ 2.3(Broker 和客户端都要)。
给每个消费者实例配置一个唯一的:
group.instance.id = your_unique_idKafka Streams 应用也是一样,每个实例设一个独立 ID。
如果 ID 重复,Broker 会踢掉冲突的客户端并报错(FencedInstanceIdException)。
Kafka 静态成员机制让消费者“有固定身份”,重启不再引起 rebalance,应用更稳定、更快恢复。
Message Delivery Semantics
Kafka的消息传递语义(Message Delivery Semantics),也就是Kafka发送、存储、消费消息时,能保证到什么程度不丢消息、不重复消息。
Kafka(或任何消息系统)都有三种语义
从生产者(Producer)角度看
Kafka 写入机制:消息被写入“分区日志”,只有当所有同步副本(ISR)都写入成功,才算“提交(committed)”。 一旦提交,只要还有一台副本存活,就不会丢消息。
早期(0.11 之前)的问题: 如果生产者发消息时网络断了,它不知道消息到底写成功没,只能重发,这样会产生重复消息。所以只能保证 “至少一次”。
Kafka 0.11+ 改进:幂等生产(Idempotent Producer) Broker 会给每个生产者分配唯一 ID,并检查消息的序列号。 如果重发的是旧的序号,就不会重复写入。 这样就能做到“不重复写”。
事务性发送(Transactional Producer) 允许一次事务性地写入多个分区或主题:要么全部成功,要么全部回滚。这是实现“exactly-once”的关键。
从消费者(Consumer)角度看
消费者需要记住自己“读到哪里了”(offset)。这决定了消息会不会重复处理或漏处理:
Exactly Once 的实现条件
Kafka 要做到真正的“恰好一次”,需要:
read_committed
模式(只读提交事务的数据)| 模式 | 含义 | 典型场景 |
|---|---|---|
| At most once | 可能丢消息,不重复 | 对实时性极高但容错性强的应用 |
| At least once | 不丢消息,可能重复 | 一般系统默认(可容忍重复) |
| Exactly once | 不丢不重 | Kafka Streams、事务性写入 |
Kafka 默认保证“至少一次”;通过“幂等 + 事务 + read_committed”,可以做到“恰好一次”。
Using Transactions
背景:为什么需要事务?
在 Kafka 中,消息可能会因为:
为了保证“消息只处理一次”,Kafka 从 0.11.0.0 版本开始引入了 事务(Transactions)机制。
事务能确保多个操作(发送消息、更新消费者偏移量)要么全部成功,要么全部失败。
Kafka 事务与传统数据库事务的区别
Kafka
的事务与数据库那种「BEGIN…COMMIT」事务有点不一样:
| 对象 | 是否支持事务 | 说明 |
|---|---|---|
| ✅ Producer(生产者) | ✔️ 是 | 可以开启事务,保证发送的多条消息是原子写入的 |
| ⚙️ Consumer(消费者) | ❌ 否 | 不能直接使用事务,但生产者可以原子地更新消费者的位移(offset) |
| 💡 效果 | 生产 + 消费 + 提交偏移量 一起变成原子操作,从而实现 exactly-once |
所以说:Kafka 的事务其实是由 生产者“帮消费者”原子地提交 offset 实现的。
实现 Exactly-Once 的三大关键要素
消费者分区独占: 每个分区同一时刻只会由一个消费者处理(Kafka Consumer Group 机制自动保证)。
生产者事务发送 生产者开启事务后,能保证:
一对一关系:一个消费者 ↔︎ 一个生产者 这样当 rebalance(再平衡)发生时,逻辑简单、可靠。 (复杂的多对多模式可以实现,但非常麻烦。)
消费者配置要求
想要实现 “exactly-once”,消费者要这样配置👇:
isolation.level=read_committed # 只读取已提交的事务消息
enable.auto.commit=false # 禁止自动提交 offset如果你不设 read_committed,消费者会看到:
这会导致数据重复或脏读。
生产者配置要求
生产者要指定一个 transactional.id:
transactional.id=my-tx-id这会告诉 Kafka:
生产者在发送时的伪代码:
producer.initTransactions(); // 初始化事务
producer.beginTransaction(); // 开始事务
// 1. 处理消息
// 2. 发送到目标 topic
// 3. 发送 offset 更新到 Kafka(表示处理完毕)
producer.commitTransaction(); // 全部成功,一起提交
// producer.abortTransaction(); // 有异常,一起撤销异常与错误处理机制
Kafka 在新版本中对事务错误分类更细了,方便开发者处理:
| 异常类型 | 含义 | 处理方式 |
|---|---|---|
RetriableException |
临时网络或超时,可自动重试 | Kafka 自动处理 |
RefreshRetriableException |
需要刷新元数据再重试 | Kafka 自动处理 |
AbortableException |
必须中止当前事务并重来 | 应用程序要 abortTransaction() |
ApplicationRecoverableException |
应用逻辑问题,需要手动恢复 | 重启 producer |
InvalidConfigurationException |
配置错误 | 修配置再启动 |
KafkaException |
其他未分类错误 | 手动处理 |
事务中止后的恢复
如果事务中止(abort):
有两种恢复策略:
seek() 回退到上次提交的
offset,重新消费。Kafka 的事务机制可以实现:
“消费消息 → 处理 → 产出新消息 → 提交偏移量” 这一整套过程的 原子性(Atomicity)。
也就是说:
举个例子:事务性消息复制器
比如我们做一个“消息复制器”:
topic-A 消费;topic-B。使用事务后,无论是网络闪断还是程序崩溃, Kafka 都能保证:👉 不会出现 “重复消息” 或 “漏消息” 的情况。
Share Groups
Share Group是什么
以前Kafka里,消费者只有一种群体:Consumer Group(消费者群体)
而现在Kafka 4.1多了一种新模式:Share Group(共享组)
简单来说:Share Group = 可以让多个消费者同时消费同一个分区里的消息的一种新模式
这解决了老机制中一个限制:一个分区在同一时间只能被一个消费者消费。
与传统 Consumer Group的区别
| 对比项 | Consumer Group(传统) | Share Group(共享组) |
|---|---|---|
| 分区分配 | 一个分区 → 仅一个消费者 | 一个分区 → 可被多个消费者共享 |
| 消费者数量 | ≤ 分区数量(多余的闲着) | 可 > 分区数量 |
| 消息确认 | 提交 offset(按批或顺序) | 每条消息单独确认(ack) |
| 消息重试 | 自己实现 | Kafka 自动跟踪重试次数 |
| 应用场景 | 严格分区顺序消费 | 高并发、多消费者并行处理 |
为什么要有Share Group
传统 consumer group 的“分区独占”机制虽然能保证顺序和负载均衡,但在一些场景下就不太够用了,比如:
💡 所以 Share Group = Kafka 版的任务队列(Task Queue)模型 有点像 RabbitMQ 的「Work Queue」或 SQS 的「Visibility Timeout」。
Share Group 是怎么工作的?
可以这样想象:
核心机制:消息锁(Record Lock)
每当消费者从 Kafka 拉取消息时:
🕒 锁时长可调:
share.record.lock.duration.ms=30000 # 默认 30 秒消费者对消息可以做四种操作:
| 操作 | 含义 | 结果 |
|---|---|---|
| ✅ Acknowledge(确认) | 处理成功 | 消息被标记为完成,不再发送 |
| 🔁 Release(释放) | 主动放弃处理 | 消息立即可被其他消费者重新领取 |
| ❌ Reject(拒绝) | 无法处理(例如数据坏了) | 消息标记为永久失败,不再投递 |
| 🕒 超时不动 | 程序崩溃或没响应 | 锁到期后自动释放,消息重新可用 |
Kafka 还提供了一些限制和保护机制
Kafka Broker 会限制:
配置项:
group.share.partition.max.record.locks这个机制让系统能自动恢复,即使有消费者宕机、延迟,也不会卡死。
多个 Share Group 之间的关系
如果同一个 topic 被多个 share group 订阅:
| 关键点 | 含义 |
|---|---|
| 🆕 新特性 | Kafka 4.1 引入的“共享组(Share Group)” |
| 💡 作用 | 允许多个消费者同时消费同一分区 |
| ⚙️ 机制 | 消息加锁(默认 30s),独立确认、重试或拒绝 |
| 🎯 优点 | 提高吞吐量,支持 finer-grained 并行处理 |
| 🔐 安全性 | 自动锁超时释放,防止消息永久卡死 |
| 🧱 场景 | 高并发处理、事件任务分发、异步任务队列 |
举个例子:
假设你有一个 topic 叫
image-jobs,每条消息是一张图片要处理。
旧模式下:
新模式(Share Group):
Replication
这部分(Replication)讲的是 Kafka 的数据复制机制,也就是 Kafka 如何在多台服务器之间保证数据不丢、不停机。我来帮你用最通俗的方式总结👇
为什么要复制(Replication)
Kafka 每个 topic 都会被分成多个 分区(partition)。 每个分区的数据会在多台机器上复制(replicate)几份,比如复制因子为 3,代表有:
👉 当 leader 挂了,Kafka 会自动切换到其中一个 follower,保证数据不丢、服务不中断。
复制机制是怎么工作的
Kafka 怎么判断一个副本“还活着”
replica.lag.time.max.ms),也会被踢出 ISR。被踢出 ISR 的副本不能被选为 leader。
Kafka 的复制模型 vs 其他系统
Kafka 没采用像 Raft 那种“多数投票(majority quorum)”机制。 它用了更高效的 ISR 模型:
👉 简单理解:
Raft 类系统靠“投票”,Kafka 靠“跟得上的那群副本(ISR)”。
如果所有副本都挂了怎么办?
Kafka 有两种策略(通过 unclean.leader.election.enable
控制):
| 策略 | 行为 | 优缺点 |
|---|---|---|
| ✅ 等待 ISR 副本恢复(默认) | 只选“同步过”的副本当新 leader | 保证数据不丢,但期间不能写入 |
| ⚡ 选第一个恢复的副本当 leader | 即使它数据不完整 | 保证能继续服务,但可能丢数据 |
Producer 写入时的可靠性选项
生产者可以设置 acks 参数控制写入确认级别:
| acks 值 | 含义 | 可靠性 | 性能 |
|---|---|---|---|
0 |
不等确认 | 可能丢消息 | 最快 |
1 |
等 leader 写入 | 可能丢部分数据 | 较快 |
all / -1 |
等所有 ISR 写完 | 最安全(不丢) | 最慢 |
另外可以通过:
min.insync.replicas = 2要求至少有 2 个副本同步成功才能确认,进一步提高可靠性。
Leader 选举机制
Kafka 集群里有一个特殊节点叫 Controller,负责管理哪些 broker 存活、谁当 leader。
当一个 broker 挂掉,controller 会:
这样即使几百个分区都要选新 leader,Kafka 也能在几秒内恢复。
Kafka 的可靠性保证
✅ 不会丢已提交(committed)的消息,前提是:
acks=all。❌ 不能保证强一致性(比如同时断网、ISR 全挂的情况会暂停写入)。
Kafka 的复制机制靠:
Log Compaction
核心概念:什么是 Log Compaction?
Kafka 的 日志压缩(Log Compaction) 是一种“更聪明的日志保留机制” 👉 它确保 每个 key 的最后一条最新消息 永远不会被删除。
对比普通的日志清理方式:
举个例子
假设 topic 中存储用户邮箱变更:
123 => bill@microsoft.com
123 => bill@gatesfoundation.org
123 => bill@gmail.comKafka 会在压缩后只保留:
123 => bill@gmail.com这意味着:
应用场景
数据库变更同步(Change Data Capture)
事件溯源(Event Sourcing)
高可用日志(Journaling)
工作机制(简化版)
Kafka 在后台有一组 log cleaner 线程,它们做的事是:
📌 过程是异步进行的,不会影响正常的读写。
🧱 保证与特点
| 特性 | 说明 |
|---|---|
| ✅ 顺序保证 | 消息顺序不会被改变,只会删除旧的 |
| ✅ Offset 不变 | 每条消息的 offset 永远固定 |
| ✅ 最新状态保留 | 每个 key 至少保留最新一条记录 |
| 🕓 可配置延迟 | min.compaction.lag.ms /
max.compaction.lag.ms 控制多久后可压缩 |
| 💀 删除机制 | 如果 value = null(称为 tombstone),表示删除该 key;标记也会在一段时间后清理掉 |
🔧 如何启用
在 topic 配置中设置:
log.cleanup.policy=compact还可以调节压缩的行为:
log.cleaner.min.compaction.lag.ms=60000 # 最少保留多久后才能被压缩
log.cleaner.max.compaction.lag.ms=3600000 # 最长多长时间后必须压缩🧩 一句话总结
Kafka 的 Log Compaction 就像是一个“自动同步的数据库快照系统”,它让你能同时:
Quotas
🎯 作用
Kafka 的配额系统是用来限制客户端使用 Broker 资源的速度,防止单个生产者或消费者过度占用资源,导致:
⚙️ 两种主要配额类型
网络带宽配额(Network Bandwidth Quotas)
请求速率配额(Request Rate Quotas)
👥 配额作用对象(Client Groups)
Kafka 根据以下信息区分客户端:
可以针对以下对象配置配额:
(user, client-id) 组合(最精确)Kafka 会优先使用最精确匹配的配额规则。
🏗️ 配置方式与优先级
Kafka 支持动态修改,不需要重启集群。
优先级顺序(从高到低):
⚡ 触发机制(Enforcement)
当 Broker 检测到客户端超出限额时:
即使客户端版本旧、不理解“延迟”响应,Broker 也会通过“静音通道(muted channel)”强制限速。
实现细节
💡 简单比喻
Kafka Quota 就像网吧管理员:
Implementation
Network Layer
网络层是一个相对简单的 NIO(非阻塞 I/O)服务器,因此这里不会进行太详细的描述。
sendfile 优化: 通过为
TransferableRecords 接口增加一个 writeTo()
方法,使得基于文件的消息集(file-backed message
set)可以直接使用操作系统提供的 transferTo() 调用。 👉
这样能跳过用户态缓冲区,直接从文件传输到网络,提高效率。
线程模型:
协议设计: Kafka 的网络通信协议被保持得非常简单, 这样做是为了 便于将来用其他语言实现客户端(比如 Java 以外的语言)。
📘 简单理解:
Kafka 的网络层类似于:
Messages
消息由三个部分组成:
将键(key)和值(value)保持为“不透明”的设计是正确的决策——当前各种序列化库的发展非常迅速,而任何特定的序列化方式都不太可能适用于所有场景。显然,具体使用 Kafka 的某个应用通常会在自身规范中指定一种固定的序列化类型。
RecordBatch
接口只是一个用于遍历消息的迭代器,同时还提供了一些专门用于在 NIO
通道中批量读取和写入消息的方法。
消息格式
Message format
Kafka 中的消息(Message,也称 Record)并不是单独写入磁盘的,而是成批(batch)写入的。一个批次称为 RecordBatch,它包含一个或多个 Record(记录)。
整体结构关系
RecordBatch
├── Header(批次头)
├── RecordsCount(记录数)
└── Records[](每条消息)
├── Record Header
├── Key / Value
└── Headers(消息头)Record Batch(记录批)
Kafka 的核心写入单元。包含多条消息及其元信息。
🧾 结构字段
| 字段 | 类型 | 说明 |
|---|---|---|
baseOffset |
int64 | 此批中第一条消息的偏移量 |
batchLength |
int32 | 整个批次的长度(字节数) |
partitionLeaderEpoch |
int32 | 分区 Leader 任期号,用于 Leader 变更追踪 |
magic |
int8 | 格式版本号(当前为 2) |
crc |
uint32 | CRC 校验码(覆盖 attributes 之后的所有数据) |
attributes |
int16 | 批次属性位(见下) |
lastOffsetDelta |
int32 | 最后一条消息相对 baseOffset 的偏移量 |
baseTimestamp |
int64 | 第一条消息的时间戳 |
maxTimestamp |
int64 | 批中最大时间戳 |
producerId |
int64 | 生产者 ID |
producerEpoch |
int16 | 生产者 Epoch |
baseSequence |
int32 | 批次中第一条消息的序列号 |
recordsCount |
int32 | 批中消息数量 |
records |
[Record] | 实际消息数组 |
⚙️ Attributes(属性位解析)
| 位范围 | 含义 |
|---|---|
| bit 0~2 | 压缩算法(0 无压缩,1 gzip,2 snappy,3 lz4,4 zstd) |
| bit 3 | 时间戳类型(0 创建时间,1 日志追加时间) |
| bit 4 | 是否事务消息(1 表示事务性) |
| bit 5 | 是否控制批(1 表示控制批,不是普通消息) |
| bit 6 | 是否有删除时间(compaction 时使用) |
| bit 7~15 | 未使用 |
🧮 CRC 校验说明
attributes
到批尾所有字节。partitionLeaderEpoch
字段(避免 Broker 修改此字段时要重算 CRC)。♻️ Log Compaction(日志压缩影响)
压缩时:
baseTimestamp
可能会改变(若首条被清理或为删除标记记录)。delete horizon
会更新。⚡Control Batch(控制批)
控制批不是普通消息,用于管理事务提交/中止。
🧭 控制记录 Key 结构
| 字段 | 类型 | 说明 |
|---|---|---|
version |
int16 | 当前版本 0 |
type |
int16 | 0 = abort(中止事务),1 = commit(提交事务) |
Value 内容对客户端是不透明的(Kafka 内部使用)。
🧱Record(单条消息)
每条消息在批次中都有相对偏移、时间戳、键值等。
🧾 Record结构字段
| 字段 | 类型 | 说明 |
|---|---|---|
length |
varint | 此条记录总长度 |
attributes |
int8 | 未使用(预留) |
timestampDelta |
varlong | 相对 baseTimestamp 的时间差 |
offsetDelta |
varint | 相对 baseOffset 的偏移差 |
keyLength |
varint | key 长度(-1 表示空) |
key |
byte[] | 消息键 |
valueLength |
varint | value 长度(-1 表示空) |
value |
byte[] | 消息内容 |
headersCount |
varint | 头部数量 |
headers |
[Header] | 消息头数组 |
🏷️Record Header(消息头)
每条记录可包含多个 header(键值对),便于携带附加元信息。
| 字段 | 类型 | 说明 |
|---|---|---|
headerKeyLength |
varint | 头部键长度 |
headerKey |
string | 头部键名 |
headerValueLength |
varint | 头部值长度 |
headerValue |
byte[] | 头部值 |
👉 使用 Protobuf 的 varint 编码格式(节省空间)。
🕰️旧版格式(Pre-0.11)
在 Kafka 0.11 之前,消息采用 Message Set 格式:
🧠总结思维导图式归纳
Message (Record)
└── RecordBatch
├── Header(批次元信息)
│ ├── baseOffset / batchLength / crc ...
│ └── attributes(压缩/事务/控制批等)
├── RecordsCount
└── Records[]
├── timestampDelta / offsetDelta
├── key / value
└── Headers[]
├── headerKey
└── headerValue💡核心要点回顾
Log
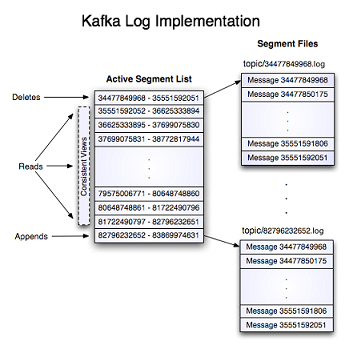
🧱主题与分区的日志目录结构
my-topic 有 两个分区 ⇒
生成两个目录:my-topic-0/
my-topic-1/📂日志文件格式
每个日志文件由连续的日志条目(log entries)组成:
[4字节: N] [N字节: message]N:当前消息的字节长度(int32)message:消息本体(N 个字节)每条消息在文件中的位置由一个唯一的 offset(偏移量) 标识。
🔢消息偏移(Offset)
🗂️日志文件命名规则
00000000000000000000.log # 第一批
00000000000000400000.log # 下一批(假设 max log size 为 4MB)⚙️记录格式版本化(Record Format Versioning)
💡为何用 offset 而非 GUID 作为消息ID
Kafka 最初考虑过使用 GUID(全局唯一 ID),但最终选择了 offset:
| 方案 | 问题/优点 | 结论 |
|---|---|---|
| GUID(随机 ID) | - 需维护 GUID → offset 的映射表 - 需要额外索引结构 - 同步磁盘开销大 |
❌ 太复杂 |
| Offset(顺序编号) | - 每个分区独立递增的计数器 - 唯一且单调递增 - 不需额外索引 - 结构更高效 |
✅ 采用此方案 |
Offset 本质上是“分区内的消息计数器”。因为 offset 在分区中唯一且递增,所以查找更简单、性能更高。
🚀设计取舍
🧭总结一句话
📘 Kafka 日志系统机制总结(Writes / Reads / Deletes / Guarantees)
Kafka 的日志(log)是 顺序写入、可顺序读取、可分段删除 的磁盘结构。它同时在性能与持久性之间做了平衡设计。
✍️Writes(写入机制)
🧱 写入规则
⚙️ 两个关键参数
| 参数 | 作用 | 意义 |
|---|---|---|
| M | 写入多少条消息后强制 flush | 控制写入条数触发磁盘刷新 |
| S | 写入多少秒后强制 flush | 控制时间间隔触发磁盘刷新 |
📜 持久化保证:系统崩溃时,最多丢失 M 条消息 或 S 秒数据。
📖Reads(读取机制)
🧩 读取方式
⚠️ 异常情况
🧮 读取步骤
查找采用一种简化的 二分查找(binary search variation),基于每个段的内存索引范围来定位。
特殊读取场景
📦 读取结果格式
单个分区(MessageSetSend)
total length : 4 bytes
error code : 2 bytes
message 1 : x bytes
...
message n : x bytes多分区(MultiMessageSetSend)
total length : 4 bytes
error code : 2 bytes
messageSetSend 1
...
messageSetSend n🗑️Deletes(删除机制)
Kafka 删除数据以“日志段(log segment)为单位”。
🕒 删除策略
| 策略类型 | 说明 |
|---|---|
| 时间策略(Time-based) | 根据日志段中最大消息时间戳判断是否过期 |
| 大小策略(Size-based) | 当分区总大小超过限制时,删除最旧段(默认关闭) |
| 混合策略 | 若任意策略命中,段即被删除 |
⚙️ 并发删除机制
为避免锁住读取操作:
🛡️Guarantees(数据一致性与恢复机制)
💾 Flush 保证
🔄启动恢复(Recovery)
重启时会执行 日志恢复过程:
offset + size < 文件长度⚠️需要防御的两类损坏
| 类型 | 原因 | 解决 |
|---|---|---|
| 截断损坏(truncation) | 崩溃导致部分写入丢失 | 自动检测并截断无效尾部 |
| 伪数据损坏(corruption) | OS 写 inode 大小成功但数据块未写完,产生垃圾数据 | CRC 校验发现并移除 |
CRC 检查确保日志不会被伪数据污染,即使系统崩溃时元数据与数据写入顺序不一致。
🧠整体机制总结
| 功能 | 机制 | 说明 |
|---|---|---|
| 写入 | 顺序追加 + 文件滚动 | 快速、顺序、高效 |
| 持久化 | M/S 控制 flush 频率 | 控制丢失范围 |
| 读取 | offset + chunk 读取 | 二分定位 + 流式返回 |
| 删除 | 按段删除 + COW 列表 | 不阻塞读 |
| 校验 | CRC32 + 截断恢复 | 防止文件损坏 |
💬一句话总结
Distribution
🧩分布式机制:消费者偏移量追踪(Consumer Offset Tracking)
Kafka 的消费者会追踪自己在每个分区中消费到的最大偏移量(offset),并且可以“提交”(commit)这些偏移量,以便在消费者重启后能从上次的位置继续消费。
Kafka 提供了一种机制,把某个消费者组的所有偏移量存储在一个特定的 broker(称为组协调者 group coordinator)上。 也就是说,一个消费者组中的所有消费者实例,都必须把它们的 offset 提交(commit)和读取(fetch)请求发送给同一个组协调者。
Kafka 根据消费者组的名称来决定哪个 broker 充当这个组的协调者。 消费者可以向任意一个 broker 发送 FindCoordinatorRequest 请求来查找自己的协调者,然后从 FindCoordinatorResponse 里获取协调者的具体信息。 之后,消费者就可以直接向这个协调者 broker 提交或读取偏移量。 如果协调者发生变化(比如挂掉或重新选举),消费者需要重新查找新的协调者。
偏移量提交可以由消费者自动提交(auto commit)或手动提交(manual commit)。
当组协调者收到一个 OffsetCommitRequest
时,它会把请求写入一个特殊的 Kafka 内部主题 ——
__consumer_offsets。
只有当该偏移量消息被该主题的所有副本都成功接收后,broker
才会向消费者返回提交成功的响应。
如果在可配置的超时时间内,这些副本没有同步成功,那么提交就会失败,消费者可能会在等待一段时间后重试。
Kafka 会定期对 __consumer_offsets
主题进行压缩(compaction),因为它只需要保留每个分区最新的偏移量记录。
同时,协调者会把这些偏移量缓存在内存中,以便快速响应消费者的读取请求。
当协调者收到一个 OffsetFetchRequest 请求时,它会直接从内存缓存中返回最近提交的偏移量。 但如果协调者刚刚启动,或者刚成为某个消费者组的新协调者(例如它现在负责的 offsets 主题分区刚切换到它),此时缓存还没加载完成。 在这种情况下,协调者会返回一个 CoordinatorLoadInProgressException 异常,表示“正在加载”,消费者需要稍等一会再重试。
💡通俗解释
你可以把 Kafka 的偏移量提交机制理解为一种“断点续播记录”:
__consumer_offsets。⚙️关键点总结
| 机制 | 说明 |
|---|---|
| 偏移量存储 | 存在特殊主题 __consumer_offsets |
| 协调者 | 每个消费者组分配一个专属 broker |
| 查找协调者 | 用 FindCoordinatorRequest 查询 |
| 提交偏移量 | OffsetCommitRequest(可能失败需重试) |
| 压缩机制 | 只保留每分区最近一次提交 |
| 快速响应 | 协调者将偏移量缓存在内存 |
| 异常处理 | 若协调者未加载完成 →
CoordinatorLoadInProgressException |
KafkaJS 官方自己的介绍是,A modern Apache Kafka client for Node.js。一个现代的Kafka Node.js客户端。
Kafka是一个消息系统,可以在系统之间安全地移动数据。根据每个组件的配置方式,它可以充当实时事件跟踪的传输器,也可以充当复制的分布式数据库。虽然它通常被称为队列,但更准确地说,它介于队列和数据库之间,兼具两种系统的特性和优势。
| 专业词 | 描述 |
|---|---|
| Cluster | Kafka 运行的机器集合 |
| Broker | 单个 Kafka 实例 |
| Topic | 主题用于组织数据。您始终可以对特定主题进行读写操作。 |
| Partition | 主题中的数据分布在多个分区中。每个分区可以看作一个按时间排序的日志文件。为了保证您按正确的顺序读取消息,同一时间只有一个消费者组成员可以从特定分区读取消息。 |
| Producer | 将数据写入一个或多个 Kafka 主题的客户端 |
| Consumer | 从一个或多个 Kafka 主题读取数据的客户端 |
| Replica | 分区通常会复制到一个或多个Broker以避免数据丢失。 |
| Leader | 虽然一个分区可能会被复制到一个或多个Broker,但单个Broker会被选为该分区的Leader,并且是唯一被允许写入或读取该分区的Broker |
| Consumer Group | 一组消费者实例的集合,以 标识groupId。在水平扩展的应用程序中,每个实例都是一个消费者,它们共同充当一个消费者组。 |
| Group Coordinator | 消费者组中的一个实例,负责为组中的消费者分配要消费的分区 |
| Offset | 分区日志中的某个点。当消费者消费完一条消息后,它会“提交”该偏移量,这意味着它会告知 Broker 消费者组已消费该消息。如果消费者组重启,它将从最高的已提交偏移量重新启动。 |
| Rebalance | 当消费者加入或离开消费者组时(例如在启动或关闭期间),该组必须“重新平衡”,这意味着必须选择一个组协调员,并且需要将分区分配给消费者组的成员。 |
| Heartbeat | heartbeatInterval
集群用来了解哪些消费者处于活动状态的机制。每个消费者必须不时地向集群领导者发送心跳请求。如果某个消费者在一定时间内
( sessionTimeout)
未能发送心跳请求,则会被视为死亡,并从消费者组中移除,从而触发重新平衡。 |
虽然我们通常将主题中的数据称为“消息”,但消息并没有统一的格式。从 Kafka 的角度来看,消息只是一个键值对,其中键和值都是字节序列。数据生产者和消费者需要就其格式达成一致。通常,您会找到纯文本的无模式消息,例如 JSON,或者强制模式的二进制格式,例如 AVRO。
纯文本JSON,JSON 无需介绍。它简单易用。我们唯一需要做的就是将消息转换Buffer为字符串并进行解析,使用 JSON 的缺点是它不强制任何类型的模式,因此在解析消息后,您无法知道哪些字段可用以及它们的类型。数据生产者无法保证字段一定会存在或其类型不会改变,这使得处理起来非常困难且容易出错。
AVRO、Protobuf 之类的数据化序列工具也可以。
docker-compose.yml
services:
controller-1:
image: apache/kafka:4.1.0
container_name: controller-1
environment:
KAFKA_NODE_ID: 1
KAFKA_PROCESS_ROLES: controller
KAFKA_LISTENERS: CONTROLLER://:9093
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@controller-1:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_LOG_DIRS: /tmp/kraft-combined-logs # 可选:指定日志目录
TZ: UTC
broker-1:
image: apache/kafka:4.1.0
container_name: broker-1
ports:
- 29092:29092
environment:
KAFKA_NODE_ID: 2
KAFKA_PROCESS_ROLES: broker
KAFKA_LISTENERS: 'PLAINTEXT://:19092,PLAINTEXT_HOST://:29092'
KAFKA_ADVERTISED_LISTENERS: 'PLAINTEXT://broker-1:19092,PLAINTEXT_HOST://127.0.0.1:29092'
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@controller-1:9093
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
# 新增:修复单节点内部主题副本问题
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_LOG_DIRS: /tmp/kraft-combined-logs # 可选:指定日志目录
TZ: UTC
depends_on:
- controller-1一个简单的demo
const { Kafka } = require('kafkajs');
const kafka = new Kafka({
clientId: 'my-app',// 客户端ID
// Kafka集群地址,把Broker的地址写到数组内,每个item为一个Broker
brokers: ['127.0.0.1:29092']
});
const create_topic = async () => {
const admin = kafka.admin();
await admin.connect();
const topics = await admin.listTopics();
console.log("已有的Topic: ", topics);
if (!topics.includes('test-topic')) {
console.log("创建Topic: test-topic");
const topicConfig = {
topics: [
{
topic: 'test-topic',//主题名
numPartitions: 1,//分区数
replicationFactor: 1//副本数
}],
waitForLeaders: true//等待leader分配完成
};
const result = await admin.createTopics(topicConfig);
console.log('topic created:', result);
}
console.log("已有的Topic: ", await admin.listTopics());
await admin.disconnect();
};
// 创建一个生产者向主题生成消息
const producer_run = async () => {
const producer = kafka.producer();
await producer.connect();
const send_result = await producer.send({
topic: 'test-topic',
messages: [
{ value: `Hello KafkaJS user! ${Date.now()}` },
],
});
console.log('send result:', send_result);
if (send_result && send_result.length > 0) {
console.log(`消息发送成功,主题: ${send_result[0].topicName}, 分区: ${send_result[0].partition}, 偏移量: ${send_result[0].baseOffset}`);
} else {
console.log('消息发送失败');
}
await producer.disconnect();
};
// 创建一个消费者从主题消费消息
const consumer_run = async () => {
let consumeCounter = 0;
const consumer = kafka.consumer({ groupId: 'test-group' });
await consumer.connect();
await consumer.subscribe({ topic: 'test-topic', fromBeginning: true });
await consumer.run({
eachMessage: async ({ topic, partition, message }) => {
consumeCounter++;
console.log(`消费消息: consumeCounter[${consumeCounter}]`, {
value: message.value.toString(),
topic,
partition
})
},
});
console.log("消费者已启动,等待消息...");
};
(async () => {
await create_topic();
await consumer_run();
setInterval(() => {
producer_run();
}, 1000);
})();可以观察到每秒都会生产一条消息到 Topic test-group
中,消费者接收到消息。
root@ser745692301841:/dev_dir/kafka-demo/kafka/kafkajs# node index.js
(node:173874) TimeoutNegativeWarning: -1761297030774 is a negative number.
Timeout duration was set to 1.
(Use `node --trace-warnings ...` to show where the warning was created)
已有的Topic: [ 'test-topic', '__consumer_offsets' ]
已有的Topic: [ 'test-topic', '__consumer_offsets' ]
{"level":"INFO","timestamp":"2025-10-24T09:10:30.820Z","logger":"kafkajs","message":"[Consumer] Starting","groupId":"test-group"}
{"level":"INFO","timestamp":"2025-10-24T09:10:30.865Z","logger":"kafkajs","message":"[ConsumerGroup] Consumer has joined the group","groupId":"test-group","memberId":"my-app-b32f3f97-93b4-4bcb-8292-e3a959f26640","leaderId":"my-app-b32f3f97-93b4-4bcb-8292-e3a959f26640","isLeader":true,"memberAssignment":{"test-topic":[0]},"groupProtocol":"RoundRobinAssigner","duration":42}
消费者已启动,等待消息...
{"level":"WARN","timestamp":"2025-10-24T09:10:31.868Z","logger":"kafkajs","message":"KafkaJS v2.0.0 switched default partitioner. To retain the same partitioning behavior as in previous versions, create the producer with the option \"createPartitioner: Partitioners.LegacyPartitioner\". See the migration guide at https://kafka.js.org/docs/migration-guide-v2.0.0#producer-new-default-partitioner for details. Silence this warning by setting the environment variable \"KAFKAJS_NO_PARTITIONER_WARNING=1\""}
send result: [
{
topicName: 'test-topic',
partition: 0,
errorCode: 0,
baseOffset: '103',
logAppendTime: '-1',
logStartOffset: '0'
}
]
消息发送成功,主题: test-topic, 分区: 0, 偏移量: 103
消费消息: consumeCounter[1] {
value: 'Hello KafkaJS user! 1761297031874',
topic: 'test-topic',
partition: 0
}
send result: [
{
topicName: 'test-topic',
partition: 0,
errorCode: 0,
baseOffset: '104',
logAppendTime: '-1',
logStartOffset: '0'
}
]
消息发送成功,主题: test-topic, 分区: 0, 偏移量: 104
消费消息: consumeCounter[2] {
value: 'Hello KafkaJS user! 1761297032873',
topic: 'test-topic',
partition: 0
}
^C客户端必须至少配置一个broker,在列表中的broker被作为种子broker用于引导客户端和加载初始元数据。
const { Kafka } = require('kafkajs')
// Create the client with the broker list
const kafka = new Kafka({
clientId: 'my-app',
brokers: ['broker1:9092', 'broker2:9092']
});应用程序的逻辑标识符,Broker可以使用它来对特定应用程序应用配额或跟踪请求,如 booking-events-processor。
kafka文档将clientId描述为,clientId是客户端的逻辑分组,其名称由客户端应用程序选择,且具有意义的名称。元组(user,clientId)定义了一个安全的客户端逻辑组,这些客户端共享用户主题和客户端ID。 配额可以应用于(user,client-id)、用户组或客户端ID组。
官方文档还说,clientId 发出请求时传递给服务器的ID字符串,通过允许在服务器端请求日志中包含逻辑应用程序名称,从而能追踪请求来源(而不仅仅是IP和端口)
因此,clientId应该在集群或水平扩展的应用程序中跨多个实例共享,但每个应用程序都不同。但是每个客户端进程尽可能都用独立的ClientID 应用+实例ID组成字符串。有些情况能共享有些不能尽量一刀切。
通常情况下,KafkaJS会自动感知到Broker集群拓扑结构的变化并做出相应,但在某些情况下,你可能希望能够动态获取种子 Broker,而不是使用静态配置的列表,这种情况下,brokers可以被设置为解析为Broker数组的异步函数。
const kafka = new Kafka({
clientId: 'my-app',
brokers: async () => {
// Example getting brokers from Confluent REST Proxy
const clusterResponse = await fetch('https://kafka-rest:8082/v3/clusters', {
headers: 'application/vnd.api+json',
}).then(response => response.json())
const clusterUrl = clusterResponse.data[0].links.self
const brokersResponse = await fetch(`${clusterUrl}/brokers`, {
headers: 'application/vnd.api+json',
}).then(response => response.json())
const brokers = brokersResponse.data.map(broker => {
const { host, port } = broker.attributes
return `${host}:${port}`
})
return brokers
}
});此发现机制仅用于获取初始 Broker 集合(即种子Broker)。成功连接到此列表中的Broker后,Kafka会通过其自身的机制来发现集群中的其余Broker。
该ssl选项可用于配置 TLS 套接字。这些选项将直接传递给 TLS 安全上下文tls.connect并用于创建 TLS 安全上下文,所有选项均可接受。
const fs = require('fs')
new Kafka({
clientId: 'my-app',
brokers: ['kafka1:9092', 'kafka2:9092'],
ssl: {
rejectUnauthorized: false,
ca: [fs.readFileSync('/my/custom/ca.crt', 'utf-8')],
key: fs.readFileSync('/my/custom/client-key.pem', 'utf-8'),
cert: fs.readFileSync('/my/custom/client-cert.pem', 'utf-8')
},
})NODE_EXTRA_CA_CERTS可用于添加自定义 CA。ssl: true如果您没有任何额外配置并希望启用 SSL,请使用此选项。
如果Kafka broker只启用了SSL(不要求客户端证书),可以这样写
const kafka = new Kafka({
clientId: 'my-app',
brokers: ['broker-ssl.mydomain.com:9093'],
ssl: true // 简写形式,默认使用 Node.js 系统信任的 CA
});| 选项 | 含义 |
|---|---|
| ssl | 启用 SSL/TLS 连接,值可以是布尔值或对象。 |
| rejectUnauthorized | 如果为
false,即使证书不是受信任的也允许连接(❗仅用于测试环境)。 |
| ca | 信任的证书颁发机构(CA)的证书,用于验证 broker 的身份。 |
| key | 客户端私钥(如果 Kafka 要求双向认证时需要)。 |
| cert | 客户端证书(对应上面的私钥)。 |
Kafka中SSL常见场景
| 场景 | 是否需要客户端证书 | 示例 |
|---|---|---|
| 单向认证(常见) | ❌ 不需要 | Kafka broker 提供自己的证书,客户端只验证它。 |
| 双向认证(客户端认证) | ✅ 需要 | Kafka broker 要求客户端也提供证书(常用于安全环境)。 |
在Kafka中,SASL(Simple Authentication and Security Layer)是一种 身份验证机制框架,用于在客户端(如生产者、消费者、管理工具等)与Kafka Broker之间进行安全认证。
简单来说:SASL是“你是谁”的验证机制,它让Kafka在接受请求之前,确认客户端的身份是否合法。
KafkaJS支持 PLAIN、SCRAM-SHA-256、SCRAM-SHA-512和AWS机制。
请注意,如果您未使用 TLS,即使凭证本身有效,代理也可能配置为拒绝您的身份验证尝试。特别提醒,在使用 TLSPLAIN作为身份验证机制时,切勿在不使用 TLS 的情况下进行身份验证,因为这会以未加密的纯文本形式传输您的凭证。
Options
| option | description | default |
|---|---|---|
| authenticationTimeout | 身份验证请求的超时时间(毫秒) | 10000 |
| reauthenticationThreshold | connections.max.reauth.ms当在代理端配置了定期重新认证时,reauthenticationThreshold在会话生存期剩余几毫秒时重新进行认证。 | 10000 |
PLAIN与SCRAM示例
new Kafka({
clientId: 'my-app',
brokers: ['kafka1:9092', 'kafka2:9092'],
// authenticationTimeout: 10000,
// reauthenticationThreshold: 10000,
ssl: true,
sasl: {
mechanism: 'plain', // scram-sha-256 or scram-sha-512
username: 'my-username',
password: 'my-password'
},
})OAUTHBEARER示例
new Kafka({
clientId: 'my-app',
brokers: ['kafka1:9092', 'kafka2:9092'],
// authenticationTimeout: 10000,
// reauthenticationThreshold: 10000,
ssl: true,
sasl: {
mechanism: 'oauthbearer',
oauthBearerProvider: async () => {
// Use an unsecured token...
const token = jwt.sign({ sub: 'test' }, 'abc', { algorithm: 'none' })
// ...or, more realistically, grab the token from some OAuth endpoint
return {
value: token
}
}
},
})该sasl对象必须包含一个名为 oauthBearerProvider 属性,一个用于返回 OAuth承载令牌的异步函数。
OAuth承载令牌必须是一个具有属性值和(可选)扩展的对象,将在SASL、OAUTHBEARER请求期间发送。
oauthbearerProvider的实现必须确保令牌在适当的时候被重用和刷线。
import { AccessToken, ClientCredentials } from 'simple-oauth2'
interface OauthBearerProviderOptions {
clientId: string;
clientSecret: string;
host: string;
path: string;
refreshThresholdMs: number;
}
const oauthBearerProvider = (options: OauthBearerProviderOptions) => {
const client = new ClientCredentials({
client: {
id: options.clientId,
secret: options.clientSecret
},
auth: {
tokenHost: options.host,
tokenPath: options.path
}
});
let tokenPromise: Promise<string>;
let accessToken: AccessToken;
async function refreshToken() {
try {
if (accessToken == null) {
accessToken = await client.getToken({})
}
if (accessToken.expired(options.refreshThresholdMs / 1000)) {
accessToken = await accessToken.refresh()
}
const nextRefresh = accessToken.token.expires_in * 1000 - options.refreshThresholdMs;
setTimeout(() => {
tokenPromise = refreshToken()
}, nextRefresh);
return accessToken.token.access_token;
} catch (error) {
accessToken = null;
throw error;
}
}
tokenPromise = refreshToken();
return async function () {
return {
value: await tokenPromise
}
}
};
const kafka = new Kafka({
// ... other required options
sasl: {
mechanism: 'oauthbearer',
oauthBearerProvider: oauthBearerProvider({
clientId: 'oauth-client-id',
clientSecret: 'oauth-client-secret',
host: 'https://my-oauth-server.com',
path: '/oauth/token',
// Refresh the token 15 seconds before it expires
refreshThreshold: 15000,
}),
},
})AWS IAM
省略跳过。
使用加密协议
强烈建议您在使用 SSL 当使用 PLAIN时,否则密码将会以明文传输。
自定义身份验证机制
KafkaJS支持自定义,身份验证机制,基本用不到,用到是在详细看看也不晚,知道这回事就行了。
https://kafka.js.org/docs/custom-authentication-mechanism
连接超时
等待连接成功的时间 毫秒,默认值为 1000。
new Kafka({
clientId: 'my-app',
brokers: ['kafka1:9092', 'kafka2:9092'],
connectionTimeout: 3000
})等待请求成功的时间(毫秒),默认值为 30000。
new Kafka({
clientId: 'my-app',
brokers: ['kafka1:9092', 'kafka2:9092'],
requestTimeout: 25000
})enforceRequestTimeout 可以通过设置为来禁用请求超时false。
new Kafka({
clientId: 'my-app',
brokers: ['kafka1:9092', 'kafka2:9092'],
enforceRequestTimeout: false
})retry选项可用于设置重试机制的配置,用于重试与Kafka的连接和API调用(使用生产者或消费者时)。
重试机制使用指数增长的随机化函数。https://kafka.js.org/docs/retry-detailed
如果超过最大重试次数,重试器将抛出异常 KafkaJSNumberOfRetriesExceeded 并中断。生产者将会错误冒泡到用户代码中,消费者将等待异常附带的重试时间(该时间基于尝试次数),然后执行完全重启。
| 选项 | 描述 | 默认 |
|---|---|---|
| maxRetryTime | 重试的最大等待时间(以毫秒为单位) | 30000 |
| initialRetryTime | 用于计算重试的初始值(以毫秒为单位)(这仍然是根据随机化因子随机化的) | 300 |
| factor | 随机化因子 | 0.2 |
| multiplier | 指数因子 | 2 |
| retries | 每次呼叫的最大重试次数 | 5 |
| restartOnFailure | 仅供消费者使用 | async()=>true |
new Kafka({
clientId: 'my-app',
brokers: ['kafka1:9092', 'kafka2:9092'],
retry: {
initialRetryTime: 100,
retries: 8
}
})restartOnFailure
消费者用尽所有重试次数后,将调用一个异步函数,用于决定是否重启消费者(本质上是重置
consumer.run)。例如,如果需要,可以在崩溃前干净地关闭资源。该函数将接收错误信息,以便根据错误类型决定是退出应用程序还是允许其重启。
该函数具有一下签名:(error: Error) => Promise<boolean>
请注意,该函数仅在 KafkaJS 认为可重试的错误发生时才会被调用。对于不可重试的错误,消费者不会重启,该restartOnFailure函数也不会被调用。请参阅此列表 (https://kafka.apache.org/protocol#protocol_error_codes) 以了解 Kafka 协议中的可重试错误,但请注意,一些其他错误在 KafkaJS 中仍被视为可重试,例如网络连接错误。
KafkaJS内置一个 STDOUT 输出 JSON格式的日志器,它还接受自定义日志创建器,方便您集成自己喜欢的日志库,共有 5 种 日志级别可供选择:NOTHING、ERROR、WARN、INFO、DEBUG,INFO为默认配置。
日志级别
const { Kafka, logLevel } = require('kafkajs')
const kafka = new Kafka({
clientId: 'my-app',
brokers: ['kafka1:9092', 'kafka2:9092'],
logLevel: logLevel.ERROR
})要在实例化后覆盖日志级别,请setLogLevel调用单个记录器。
const { Kafka, logLevel } = require('kafkajs')
const kafka = new Kafka({
clientId: 'my-app',
brokers: ['kafka1:9092', 'kafka2:9092'],
logLevel: logLevel.ERROR
})
kafka.logger().setLogLevel(logLevel.WARN)
const producer = kafka.producer(...)
producer.logger().setLogLevel(logLevel.INFO)
const consumer = kafka.consumer(...)
consumer.logger().setLogLevel(logLevel.DEBUG)
const admin = kafka.admin(...)
admin.logger().setLogLevel(logLevel.NOTHING)环境变量KAFKAJS_LOG_LEVEL也可以使用,并且它优先于代码中的配置,例如:
KAFKAJS_LOG_LEVEL=info node code.js为了允许自定义套接字配置,客户端接受一个可选 socketFactory 属性,该属性将用于构造任何套接字。
socketFactory 应该是一个返回与之兼容的对象的函数 net.Socket
const { Kafka } = require('kafkajs')
// Example socket factory setting a custom TTL
const net = require('net')
const tls = require('tls')
const myCustomSocketFactory = ({ host, port, ssl, onConnect }) => {
const socket = ssl
? tls.connect(
Object.assign({ host, port }, ssl),
onConnect
)
: net.connect(
{ host, port },
onConnect
)
socket.setKeepAlive(true, 30000)
return socket
}
const kafka = new Kafka({
clientId: 'my-app',
brokers: ['kafka1:9092', 'kafka2:9092'],
socketFactory: myCustomSocketFactory,
})代理支持
可以使用自定义套接字工厂实现对代理流量的支持,在下面的实例中,我们使用 proxy-chain 与代理服务器集成,但只要实现了套接字工场接口,就可以使用任何其他代理库。
const tls = require('tls')
const net = require('net')
const { createTunnel, closeTunnel } = require('proxy-chain')
const socketFactory = ({ host, port, ssl, onConnect }) => {
const socket = ssl ? new tls.TLSSocket() : new net.Socket()
createTunnel(process.env.HTTP_PROXY, `${host}:${port}`)
.then((tunnelAddress) => {
const [tunnelHost, tunnelPort] = tunnelAddress.split(':')
socket.setKeepAlive(true, 60000)
socket.connect(
Object.assign({ host: tunnelHost, port: tunnelPort, servername: host }, ssl),
onConnect
)
socket.on('close', () => {
closeTunnel(tunnelServer, true)
})
})
.catch(error => socket.emit('error', error))
return socket
}生成消息
要将消息发布到Kafka,您必须创建一个生产者,只需调用 producer 客户端的函数即可创建它:
const producer = kafka.producer();或带有选项
const producer = kafka.producer({
allowAutoTopicCreation: false,
transactionTimeout: 30000
});| 选项 | 描述 | 默认 |
|---|---|---|
| createPartitioner | 详情请看Custom Partitioner | null |
| retry | 详情请看 Producer Retry | null |
| metadataMaxAge | 即使我们没有看到任何分区领导层的变化,我们也会强制刷新元数据,以主动发现任何新的Broker或分区 | 300000-5min |
| allowAutoTopicCreation | 查询不存在主题的元数据时允许创建主题 | true |
| transactionTimeout | 事务协调器在主动中止正在进行的事务之前等待生产者事务状态更新的最长时间(以毫秒为单位)。如果此值大于代理 transaction.max.timeout.ms 中的设置,则请求将失败并显示错误 InvalidTransactionTimeout | 60000 |
| idempotent | 实验性,启用后,生产者将确保每条消息仅写入一次,Acks必须设置为-1(全部),重试次数默认为 MAX_SAFE_INTEGER | false |
| maxInFlightRequests | 任何时间点可进行的最大请求数,如果为false,则无限制 | null(no limit) |
该方法send用于将消息发布到Kafka集群。
// 创建一个生产者向主题生成消息
const producer_run = async () => {
const producer = kafka.producer();
await producer.connect();
const send_result = await producer.send({
topic: 'test-topic',
messages: [
{ key: 'key1', value: `key1 Hello KafkaJS user! ${Date.now()}` },
{ key: 'key2', value: `key2 Hello KafkaJS user! ${Date.now()}` },
],
});
console.log('send result:', send_result);
if (send_result && send_result.length > 0) {
console.log(`消息发送成功,主题: ${send_result[0].topicName}, 分区: ${send_result[0].partition}, 偏移量: ${send_result[0].baseOffset}`);
} else {
console.log('消息发送失败');
}
await producer.disconnect();
};具有自定义分区的示例:
const create_topic = async () => {
const admin = kafka.admin();
await admin.connect();
let topics = await admin.listTopics();
console.log("已有的Topic: ", topics);
if (topics.includes('test-topic'))
await admin.deleteTopics({ topics: ['test-topic'] });
topics = await admin.listTopics();
console.log("删除test-topic后,已有的Topic: ", topics);
if (!topics.includes('test-topic')) {
console.log("创建Topic: test-topic");
const topicConfig = {
topics: [
{
topic: 'test-topic',//主题名
numPartitions: 2,//分区数
replicationFactor: 1//副本数
}],
waitForLeaders: true//等待leader分配完成
};
const result = await admin.createTopics(topicConfig);
console.log('topic created:', result);
}
console.log("已有的Topic: ", await admin.listTopics());
await admin.disconnect();
};
// 创建一个生产者向主题生成消息
const producer_run = async () => {
const producer = kafka.producer();
await producer.connect();
const send_result = await producer.send({
topic: 'test-topic',
messages: [
{ key: 'key1', value: `key1 Hello KafkaJS user! ${Date.now()}`, partition: 0 },
{ key: 'key2', value: `key2 Hello KafkaJS user! ${Date.now()}`, partition: 1 },
],
});
console.log('send result:', send_result);
if (send_result && send_result.length > 0) {
console.log(`消息发送成功,主题: ${send_result[0].topicName}, 分区: ${send_result[0].partition}, 偏移量: ${send_result[0].baseOffset}`);
} else {
console.log('消息发送失败');
}
await producer.disconnect();
};
// 创建一个消费者从主题消费消息
const consumer_run = async () => {
let consumeCounter = 0;
const consumer = kafka.consumer({ groupId: 'test-group' });
await consumer.connect();
await consumer.subscribe({ topic: 'test-topic', fromBeginning: true });
await consumer.run({
eachMessage: async ({ topic, partition, message }) => {
consumeCounter++;
console.log(`消费消息: consumeCounter[${consumeCounter}]`, {
value: message.value.toString(),
topic,
partition
})
},
});
console.log("消费者已启动,等待消息...");
};send方法具有以下签名:
await producer.send({
topic: <String>,
messages: <Message[]>,
acks: <Number>,
timeout: <Number>,
compression: <CompressionTypes>,
})| 属性 | 描述 | 默认 |
|---|---|---|
| 话题 | 主题名称 | |
| 消息 | 对象数组 | |
| 确认 | 控制所需确认的数量 -1=所有同步副本必须确认(默认)、0=无需确认、1=仅等待领导者确认 | -1所有同步副本必须确认 |
| 暂停 | 等待响应的时间(毫秒) | 30000 |
| 压缩 | 压缩编解码器 | CompressionTypes.None |
单个Message结构
| 属性 | 描述 | 默认 |
|---|---|---|
| key | 用于分区 | |
| value | 您的消息内容,该值可以是缓冲区、字符串、或null,发送到Kafka时,该值始终以字节编码,消费者在消费时需要根据您的架构来解释该值。 | |
| partition | 将消息发送到哪个分区,如果省略此属性,则如何确定分区的详细信息 | |
| timestamp | 消息创建时的时间戳 | Date.now() |
| headers | 与消息关联的元数据 |
Key
消息 key 用于决定将消息发送到哪个分区,这对于确保与同一聚合相关的消息按顺序处理非常重要,例如,如果使用 orderId 作为键,则可以确保与该订单相关的所有消息都按顺序处理。
默认情况下,生产者配置为使用以下逻辑分发消息:
Timestamp
每条消息都有一个时间戳,该事件戳采用UTC时间戳格式,精度为毫秒,是一个字符串,如果未提供时间戳,生产者将使用当前时间作为时间戳。消息被消费时,代理可能会根据主题配置覆盖此时间戳:
Headers
Kafka v0.11 引入了记录头,允许您的消息携带额外的元数据,要随消息一起发送记录头,请 headers 在值中包含键。
await producer.send({
topic: 'topic-name',
messages: [{
key: 'key1',
value: 'hello world',
headers: {
'correlation-id': '2bfb68bb-893a-423b-a7fa-7b568cad5b67',
'system-id': 'my-system',
}
}]
})header value 可以是 字符串或字符串数组。
要同时生产到多个Topic,请使用 sendBatch。例如,在两个Topic之间迁移时,此功能非常有用。
const topicMessages = [
{
topic: 'topic-a',
messages: [{ key: 'key', value: 'hello topic-a' }],
},
{
topic: 'topic-b',
messages: [{ key: 'key', value: 'hello topic-b' }],
},
{
topic: 'topic-c',
messages: [
{
key: 'key',
value: 'hello topic-c',
headers: {
'correlation-id': '2bfb68bb-893a-423b-a7fa-7b568cad5b67',
},
}
],
}
]
await producer.sendBatch({ topicMessages })sendBatch 具有与send相同的函数签名,但 topic 和 messages 被替换为 topicMessages:
await producer.sendBatch({
topicMessages: <TopicMessages[]>,
acks: <Number>,
timeout: <Number>,
compression: <CompressionTypes>,
})可以为生产者分配一个自定义的分区器,分区器是一个函数,它返回另一个负责分区选择的函数,如下所示:
const MyPartitioner = () => {
return ({ topic, partitionMetadata, message }) => {
// select a partition based on some logic
// return the partition number
return 0
}
}partitionMetadata 是具有以下结构的分区数组:
{ partitionId: <NodeId>, leader: <NodeId> }例子:
[
{ partitionId: 1, leader: 1 },
{ partitionId: 2, leader: 2 },
{ partitionId: 0, leader: 0 }
]createPartitioner 要使用自定义分区器,请在创建 producer 时使用该选项。
kafka.producer({ createPartitioner: MyPartitioner })KafkaJS 附带2个分区器:DefaultPartitioner 和 LegacyPartitioner
应该与Java Kafka客户端自带的默认分区器兼容,这对于满足连接多个Topic时共同分区的需求 DefaultPartitioner 非常重要,不然 KafkaJS和Java同时用,可想而知完蛋了。
该选项 retry 可用于为生产者定义配置。在客户端配置 Client Configuration 部分我们了解过了。
由于kafkaJS的目标是占用空间尽可能小,依赖性尽可能少,因此只有GZIP编码器是核心功能的一部分,其他编解码器可作为包使用。
GZIP
const { CompressionTypes } = require('kafkajs')
async () => {
await producer.send({
topic: 'topic-name',
compression: CompressionTypes.GZIP,
messages: [
{ key: 'key1', value: 'hello world' },
{ key: 'key2', value: 'hey hey!' }
],
})
}消费者知道如何解压缩GZIP,因此无需进一步的工作。
Snappy
Snappy 使用包 kafkajs-snappy 可以被支持。https://github.com/tulios/kafkajs-snappy
npm install --save kafkajs-snappy
# yarn add kafkajs-snappyconst { CompressionTypes, CompressionCodecs } = require('kafkajs')
const SnappyCodec = require('kafkajs-snappy')
CompressionCodecs[CompressionTypes.Snappy] = SnappyCodecLZ4
LZ4 使用包 kafkajs-lz4 可以被支持。https://github.com/indix/kafkajs-lz4
npm install --save kafkajs-lz4
# yarn add kafkajs-lz4const { CompressionTypes, CompressionCodecs } = require('kafkajs')
const LZ4 = require('kafkajs-lz4')
CompressionCodecs[CompressionTypes.LZ4] = new LZ4().codecZSTD
Zstandard 使用包 @kafkajs/zstd。https://github.com/kafkajs/zstd
npm install --save @kafkajs/zstd
# yarn add @kafkajs/zstdconst { CompressionTypes, CompressionCodecs } = require('kafkajs')
const ZstdCodec = require('@kafkajs/zstd')
CompressionCodecs[CompressionTypes.ZSTD] = ZstdCodec()OTHER
任何其他编解码器都可以使用现有库轻松实现。
编解码器是一个具有两个 async 函数的对象,compress 和 decompress。导入库并定义编解码器对象:
const MyCustomSnappyCodec = {
async compress(encoder){
return someCompressFunction(encoder.buffer);
},
async decompress(buffer){
return someDecompressFunction(buffer);
}
}现在我们有了编解码器对象,我们可以将其包装在一个函数中并将其添加到实现中:
const { CompressionTypes, CompressionCodecs } = require('kafkajs')
CompressionCodecs[CompressionTypes.Snappy] = () => MyCustomSnappyCodec新的编解码器现在可以与方法一起使用send,例如:
await producer.send({
topic: 'topic-name',
compression: CompressionTypes.Snappy,
messages: [
{ key: 'key1', value: 'hello world' },
{ key: 'key2', value: 'hey hey!' }
],
})KafkaJS提供了一个简单的接口来支持Kafka事务(事务需要Kafka版本>=0.11)
通过异步调用来初始化事务
producer.transaction()。返回的事务对象包含方法
send 和 sendBatch
其签名与生产者相同。完成后调用 transaction.commit() 或
transaction.abort()
来结束事务。具有事务感知的消费者只会读取已提交的消息。
Kafka要求事务生产者具有以下配置来保证 Exactly-once-semantics
“in-flight requests”(飞行中请求)指的是生产者(Producer)向 Kafka Broker 发送的请求,但尚未收到 Broker 确认(acknowledgement)的那些请求。 简单来说,就是“已发出但未确认”的消息批次或请求,这些请求正“在飞行中”(in flight),等待 Broker 处理并返回结果。
max.in.flight.requests.per.connection = 1:限制每个连接的飞行中请求(in-flight
requests)最多 1
个。这防止消息乱序(out-of-order),因为如果允许多个请求并行,Broker
故障时可能导致重试时顺序颠倒,破坏原子性。acks = all (-1):等待所有 ISR(In-Sync
Replicas,在同步副本)确认写入。这确保耐久性(durability),消息不会在部分副本丢失后被视为“成功”。retries = Integer.MAX_VALUE(或无限重试):启用无限重试以处理瞬时故障(如网络抖动),结合
PID(Producer ID)和序列号机制,确保重试不会产生重复。额外前提:
enable.idempotence = true(幂等性)。transactional.id(事务
ID),用于协调和恢复。transaction.state.log.replication.factor >= 1 和
transaction.state.log.min.isr >= 1(单节点可设为
1)。如果缺少这些,Kafka 只能保证 At-Least-Once 或 At-Most-Once,而非 EoS。
// 创建一个生产者向主题生成消息
const producer_run = async () => {
const producer = kafka.producer({
transactionalId: 'my-transactional-producer', // 为producer指定一个唯一的事务ID
maxInFlightRequests: 1, // 只能有一个飞行请求
idempotent: true // 开启幂等
});
await producer.connect();
const transaction = await producer.transaction();
try {
await transaction.send({
topic: 'test-topic',
messages: [
{ key: 'key1', value: `key1 Hello KafkaJS user! ${Date.now()}`, partition: 0 },
{ key: 'key2', value: `key2 Hello KafkaJS user! ${Date.now()}`, partition: 1 },
],
});
// throw new Error("模拟错误,测试事务回滚");
await transaction.commit();
console.log('Transaction committed successfully');
} catch (err) {
await producer.disconnect();
console.error('Error in producer:', err);
}
await producer.disconnect();
};transactionalId 在 Kafka 事务中不仅是唯一标识,更是“围栏”(fencing)机制的核心,用于隔离旧的“僵尸”生产者实例(zombie instances)。这确保了 Exactly-Once Semantics (EoS) 在流处理(如 read-process-write 管道)中的可靠性,尤其在分布式应用中,生产者可能因故障重启或多副本竞争。
为什么 transactionalId 需要这样设计
input-topic-0)的生产者 ID
不一致,重试可能导致重复处理(e.g., 订单重复扣款)。固定
transactionalId
绑定到特定分区,确保整个周期的幂等性和顺序。如果不正确选择 ID:
推荐选择方案:编码主题 + 分区
您提到的简单方案
"myapp-producer-" + topic + "-" + partition
是最佳实践,尤其适合分区级流处理:
格式示例:
"myapp-producer-user-events-0""myapp-producer-orders-3"优点:
高级变体(多输入主题):
如果管道涉及多个输入主题,用组合:"myapp-producer-" + inputTopic + "-" + partition + "-" + instanceId(instanceId 如主机名或线程 ID,防多实例冲突)。
对于 Streams 应用,Kafka Streams 内部自动生成基于
application.id + 分区,但自定义生产者需手动编码。
// 为每个分区创建独立生产者(或动态 ID)
const getTransactionalId = (topic, partition) => `myapp-producer-${topic}-${partition}`;
const producer = kafka.producer({
transactionalId: getTransactionalId('test-topic', 0), // 固定分区 ID
idempotent: true,
// ... 其他 EoS 配置
});多分区:用线程池或 Streams 库,每个分区一个生产者实例。
https://www.confluent.io/blog/transactions-apache-kafka/
要将偏移量作为事务的一部分发送,即只有事务成功时才会提交偏移量,请使用
transaction.sendOffsets()
方法。当我们希望事务在“消费-转换-生产”循环中生成来自消费者的消息时,这都是必需的
await transaction.sendOffsets({
consumerGroupId, topics
})topics具有以下结构:
[{
topic: <String>,
partitions: [{
partition: <Number>,
offset: <String>
}]
}]Kafka中消费者组(groupId)、主题(topic)、分区(partition)三者之间的关系,是Kafka高可扩展性和高可靠性的核心机制之一。
| 概念 | 说明 |
|---|---|
| Topic(主题) | 类似一个“消息队列”的名字,比如
orders、logs。 |
| Partition(分区) | 每个主题被划分为多个分区(partition 0, 1, 2...),每个分区是一个有序、不可变的消息日志文件。 |
| Consumer Group(消费者组) | 多个消费者(consumer instance)组成一个组,通过 groupId
标识,用来实现消息的分布式消费。 |
一个主题Topic 可以有多个分区(Partition)
Topic: orders
Partitions: 0, 1, 2假设我们有:主题 orders 分区数 3 消费者组ID group-A
| Consumer 实例 | 分配的分区 |
|---|---|
| consumer-1 | partition 0 |
| consumer-2 | partition 1 |
| consumer-3 | partition 2 |
即:一个分区同组内能有一个消费者读取,但多个消费者组可以读取同一个分区
当组内的消费者数量变化时(例如新消费者加入、旧消费者崩溃),Kafka会进行Rebalance再平衡:
| 分区数 | 消费者数 | 结果 |
|---|---|---|
| 3 | 3 | 每个消费者1个分区 ✅ |
| 3 | 2 | 1个消费者会消费2个分区 ✅ |
| 3 | 4 | 有1个消费者闲置 ❌ |
即使是同一个Topic,不同的groupId会各自维护offset消费进度,它们不会互相影响。
举例:
这就是Kafka支持一条消息可被多个独立系统同时消费的原因(日志分析系统、警告系统、数据仓库等可共享同一Topic)。
可视化示意图
Topic: orders
├── Partition 0 ───► consumer-1 (group-A)
├── Partition 1 ───► consumer-2 (group-A)
├── Partition 2 ───► consumer-3 (group-A)
Topic: orders
├── Partition 0 ───► consumer-X (group-B)
├── Partition 1 ───► consumer-Y (group-B)
├── Partition 2 ───► consumer-Z (group-B)group-A 和 group-B 都在消费同一个Topic,但各自维护自己的消费进度。
Kafka为每个消费者组维护消费进度 Offset
__consumer_offsets
├── key: (groupId, topic, partition)
└── value: offset举例
(groupId=group-A, topic=orders, partition=1) → offset=1056所以:
消费者组允许一组机器或进程协调对Topic列表的访问,从而在消费者之间分配负载,当一个消费者发生故障时,负载会自动分配给组中的其他成员。从Kafka Broker的角度来看, 消费者组在集群内必须具有唯一的组ID。
创建消费者
const consumer = kafka.consumer({ groupId: 'test-group' });订阅一些主题
await consumer.connect();
await consumer.subscribe({ topics: ['topic-A'] })
// You can subscribe to multiple topics at once
await consumer.subscribe({ topics: ['topic-B', 'topic-C'] })
// It's possible to start from the beginning of the topic
await consumer.subscribe({ topics: ['topic-D'], fromBeginning: true })或者,您可以订阅任何与正则表达式匹配的Topic
await consumer.connect()
await consumer.subscribe({ topics: [/topic-(eu|us)-.*/i] })提供正则表达式时,消费者将不会匹配订阅后创建的主题。如果您的代理有
topic-A 和 topic-B,并且您订阅了 /topic-.*,那么 topic-C
创建后,您的消费者将不会自动订阅 topic-C。
KafkaJS 为您提供了两种处理数据的方法 eachMessage 和
eachBatch。
该 eachMessage
处理程序提供了一个便捷易用的API,可以一次向您的函数提供一条消息。它基于
eachBatch
实现,并会按照您配置的间隔自动提交偏移量和心跳。如果您刚开始使用Kafka消费者,那么这是一个不错的起点。
// 创建一个消费者从主题消费消息
const consumer_run = async () => {
let consumeCounter = 0;
const consumer = kafka.consumer({ groupId: 'test-group', sessionTimeout: 30000 });
await consumer.connect();
await consumer.subscribe({ topic: 'test-topic', fromBeginning: true });
await consumer.run({
eachMessage: async ({ topic, partition, message, heartbeat, pause }) => {
consumeCounter++;
console.log(`消费消息: consumeCounter[${consumeCounter}]`, {
key: message.key.toString(),
value: message.value.toString(),
topic,
partition,
headers: message.headers,
})
},
});
console.log("消费者已启动,等待消息...");
};请注意,eachMessage 处理程序的阻塞时间不应超过配置的
session
timeout,否则消费者将被从组中移除。如果您的工作负载导致单个消息的处理时间非常慢,那么您应该增加会话超时时间,或者定期使用
heartbeat 处理程序负载中公开的函数。该 pause
函数提供了方便的调用
consumer.pause({topic, partitions:[partition]})。它将暂停当前Topic
Partition,并返回一个允许您稍后恢复消费的函数。
有些用例需要直接处理批次。此处理程序将为您的函数提供批次,并提供一些实用函数,以提高您的代码灵活性:resolveOffset、
hearbeat、commitOffsetsIfNecessary、uncommittedOffsets、isRunning、isStale、pause。所有已解析的偏移量将在函数执行后自动提交。
与使用 eachBatch 相比,直接使用 eachMessage 是被认为更高级的用例,因此您必须了解会话超时和心跳是如何连接的。
// 创建一个消费者从主题消费消息
const consumer_run = async () => {
let consumeCounter = 0;
const consumer = kafka.consumer({ groupId: 'test-group' });
await consumer.connect();
await consumer.subscribe({ topic: 'test-topic', fromBeginning: true });
await consumer.run({
eachBatchAutoResolve: true,
eachBatch: async ({
batch,
resolveOffset,
heartbeat,
commitOffsetsIfNecessary,
uncommittedOffsets,
isRunning,
isStale,
pause
}) => {
for (let message of batch.messages) {
consumeCounter++;
console.log(`消费消息: consumeCounter[${consumeCounter}]`, {
topic: batch.topic,
partition: batch.partition,
highWatermark: batch.highWatermark,
message: {
offset: message.offset,
key: message.key.toString(),
value: message.value.toString(),
headers: message.headers,
}
});
// 标记已消费
resolveOffset(message.offset);
// 心跳
await heartbeat();
}
}
});
console.log("消费者已启动,等待消息...");
};Promise<void>
可用于根据消费者配置中设置的 heartbeatInterval
值向Broker发送心跳,这意味着如果您在 heartbeatInterval 之前调用
heartbeat(),它将被忽略。commitOffsetsNecessary(offsets?):Promise<void>
用于基于 autoCommit
配置(autoCommitInterval)和(autoCommitThreshold)提交偏移量。请注意,如果未调用
commitOffsetsIfNecessary,则autocommit不会在eachBatch中发生而是在eachBatch调用后。默认情况下,eachMessage对每个分区中的每条消息按顺序调用,为了同时处理多条消息,可以增加 partitionConsumedConcurrently 选项
// 创建一个消费者从主题消费消息
const consumer_run = async () => {
let consumeCounter = 0;
const consumer = kafka.consumer({ groupId: 'test-group' });
await consumer.connect();
await consumer.subscribe({ topic: 'test-topic', fromBeginning: true });
consumer.run({
partitionsConsumedConcurrently: 2,
eachMessage: async ({ topic, partition, message }) => {
consumeCounter++;
console.log(`消费消息: consumeCounter[${consumeCounter}]`, {
topic,
partition,
message: {
offset: message.offset,
key: message.key.toString(),
value: message.value.toString(),
headers: message.headers,
}
});
}
});
console.log("消费者已启动,等待消息...");
};同一分区中的消息仍保证按顺序处理,但来自多个分区的消息可以同时处理。如果消息 eachMessage 由异步工作(例如网络请求或其他I/O)组成,这可以提高性能。如果 eachMessage 消息完全同步,则不会有任何影响。
如果您使用 eachBatch 情况也是如此,给定
partitionsConsumedConcurrently > 1,将能够同时处理多个批次。
设置 partitionsConsumedConcurrently 的指导原则是,该值不应大于实际使用的分区数量,根据您的工作负载是否受CPU限制,将其设置为高于逻辑CPU核心数可能也无益,建议从较低的值开始,然后测量增加该值是否能提高吞吐量。
消息总是以批次形式从Kafka获取,即使使用eachMessage处理程序。所有解析的偏移量将从处理整个批次后提交到Kafka。
在批次期间定期提交偏移量允许消费者从组再平衡、过时元数据和其他问题中恢复,而无需完成整个批次。然而,更频繁的提交会增加网络流量并减慢处理速度。Auto-commit提供了更多灵活性来提交偏移量;有两种可用模式;
autoCommitInterval:消费者将在给定时间段后提交偏移量,例如,2秒,值以毫秒为单位,默认值
null
consumer.run({
autoCommitInterval: 5000,
// ...
})autoCommitThreshold:消费者将在解析给定数量的消息后提交偏移量,例如,一百条消息。默认值
null
consumer.run({
autoCommitThreshold: 100,
// ...
})同时使用两种模式也是可能的,消费者将在任何一种用例(间隔或消息数量)发生时提交偏移量。
autoCommit:高级选项,用于完全禁用自动提交,相反,您可以手动提交偏移量,默认值:true。
当禁用 autoCommit 时,您仍然可以手动提交消息偏移量,有几种不同的方式;
消费者的 commitOffsets
是最低级别的选项,它会忽略所有其他自动提交设置,但这样做允许将已提交的偏移量设置为任何偏移量,并一次提交各种偏移量。这在构建处理重置工具时非常有用。它只能在
consumer.run
之后调用。提交偏移量不会改变我们开始消费后将消费的下一个消息,而是仅用于确定从哪个位置开始。要立即更改消费消息的偏移量,您应该使用
seek。
consumer.run({
autoCommit: false,
eachMessage: async ({ topic, partition, message }) => {
// 以某种方式处理消息
},
});
consumer.commitOffsets([
{ topic: 'topic-A', partition: 0, offset: '1' },
{ topic: 'topic-A', partition: 1, offset: '3' },
{ topic: 'topic-B', partition: 0, offset: '2' }
])// 创建一个消费者从主题消费消息
const consumer_run = async () => {
let consumeCounter = 0;
const consumer = kafka.consumer({ groupId: 'test-group' });
await consumer.connect();
await consumer.subscribe({ topic: 'test-topic', fromBeginning: false });
consumer.run({
autoCommit: false,
partitionsConsumedConcurrently: 1,
eachMessage: async ({ topic, partition, message }) => {
consumeCounter++;
// 消费前直接提交 Offset
await consumer.commitOffsets([
{ topic: topic, partition: partition, offset: (Number(message.offset) + 1).toString() }
]);
// Offset提交成功再消费
console.log(`消费消息: consumeCounter[${consumeCounter}]`, {
topic,
partition,
message: {
offset: message.offset,
key: message.key.toString(),
value: message.value.toString(),
headers: message.headers,
}
});
}
});
console.log("消费者已启动,等待消息...");
};您不必将已消费的偏移量存储在Kafka中,可以存在自己的SQL数据库,存储在Kafka外部的偏移量的通常使用模式如下:
一个消费消息转换再提交到其他主题的样例
const { Kafka, Partitioners } = require('kafkajs');
const kafka = new Kafka({
clientId: 'e2e-tx-app',
brokers: ['127.0.0.1:29092'],
retry: { retries: Infinity }, // 无限重试
});
const producer = kafka.producer({
transactionalId: 'e2e-tx-source-topic-0', // 固定分区级 ID(防僵尸实例)
idempotent: true, // 启用幂等性
maxInFlightRequests: 1, // 飞行请求=1,确保顺序
createPartitioner: Partitioners.LegacyPartitioner, // v2.x 兼容
});
const consumer = kafka.consumer({ groupId: 'e2e-group' });
const run = async () => {
await producer.connect();
await producer.initTransactions(); // 初始化事务
await consumer.connect();
await consumer.subscribe({
topics: ['source-topic'],
fromBeginning: true,
});
await consumer.run({
autoCommit: false, // 禁用自动提交,手动事务控制
eachBatchAutoResolve: false, // 手动解析 offset
eachBatch: async ({ batch, resolveOffset, heartbeat }) => {
const topic = batch.topic;
const partition = batch.partition;
const offsets = []; // 收集已处理 offset
for (let message of batch.messages) {
await heartbeat(); // 发送心跳,防再平衡
// 转换处理(示例:假设 value 是数字字符串)
const originalValue = parseInt(message.value.toString());
const processedValue = originalValue + 1;
const processedMessage = { value: processedValue.toString() };
try {
await producer.beginTransaction(); // 开始新事务(每个消息一个事务,或批量)
// 发送处理后消息到目标 topic
const sendResult = await producer.send({
topic: 'target-topic',
messages: [processedMessage],
acks: -1, // 等待所有副本
});
// 将消费 offset 加入事务(原子提交)
const consumerOffset = parseInt(message.offset) + 1; // +1 为下一个 offset
await producer.sendOffsetsToTransaction(
[{ topic, partition, offset: consumerOffset.toString() }], // 已处理 offset
'e2e-group' // 消费者组 ID
);
await producer.commitTransaction(); // 原子提交:消息 + offset
console.log(`Processed: ${originalValue} -> ${processedValue}, offset: ${message.offset}`);
resolveOffset(message.offset); // 标记为已解析(可选,事务已处理)
offsets.push(consumerOffset);
} catch (error) {
await producer.abortTransaction(); // 回滚:不提交消息或 offset
console.error('Transaction aborted:', error);
// 可重试或跳过此消息
break; // 或 continue,根据策略
}
}
// 可选:批量 commitOffsetsIfNecessary(offsets) 如果不全用事务
},
});
};
run().catch(console.error);
// 优雅关闭
process.on('SIGINT', async () => {
await consumer.disconnect();
await producer.disconnect();
process.exit(0);
});消费者组在开始获取消息时将使用最新提交的偏移量,如果偏移量无效或未定义,fromBeginning则定义消费者组的行为。这可以在订阅主题时配置:
await consumer.subscribe({ topic: ['test-topic'], fromBeginning: true });
await consumer.subscribe({ topic: ['test-topic'], fromBeginning: false });当 fromBeginning 为true时,客户端组将使用最早的偏移量,如果设置为 false,则将使用最新的偏移量,默认值为 false。
export class Kafka {
constructor(config: KafkaConfig)
producer(config?: ProducerConfig): Producer
consumer(config: ConsumerConfig): Consumer
admin(config?: AdminConfig): Admin
logger(): Logger
}
export interface ConsumerConfig {
groupId: string
partitionAssigners?: PartitionAssigner[]
metadataMaxAge?: number
sessionTimeout?: number
rebalanceTimeout?: number
heartbeatInterval?: number
maxBytesPerPartition?: number
minBytes?: number
maxBytes?: number
maxWaitTimeInMs?: number
retry?: RetryOptions & { restartOnFailure?: (err: Error) => Promise<boolean> }
allowAutoTopicCreation?: boolean
maxInFlightRequests?: number
readUncommitted?: boolean
rackId?: string
}
export type PartitionAssigner = (config: {
cluster: Cluster
groupId: string
logger: Logger
}) => Assigner| 选项 | 描述 | 默认 |
|---|---|---|
| partitionAssigners | 分区分配器列表,用于决定消费者如何在组内分配分区 | [PartitionAssigners.roundRobin] |
| sessionTimeout | 会话超时时间(毫秒)用于检测消费者是否失效,消费者会周期性向broker发送心跳包表示存活,如果broker在超时时间内未收到心跳,就会将该消费者从组中移除,并触发再平衡 | 30000 |
| rebalanceTimeout | 再平衡超时时间(毫秒),协调者在触发消费者组再平衡时,等待每个成员重新加入的最长时间 | 60000 |
| heartbeatInterval | 心跳间隔(毫秒),消费者向协调者发送心跳的期望间隔,用于保证会话活动状态,该值必须小于sessionTimeout | 3000 |
| metadataMaxAge | 元数据最大存活时间(毫秒),即使分区领导者未变化,过了这个时间也会强制刷新元数据,以主动发现新的broker或分区 | 300000(5分钟) |
| allowAutoTopicCreation | 允许在查询元数据时自动创建不存在的主题 | true |
| maxBytesPerPartition | 每个分区返回的最大数据量(字节),必须至少等于服务器允许的最大消息大小,否则生产者可能发送的消息比消费者能拉取的还大,导致消费者卡在大消息上 | 1048576(1MB) |
| minBytes | 服务器在返回拉取请求结果前,必须积累的最小数据量(字节),若数据不足,将等待maxWaitTimeInMS时间 | 1 |
| maxBytes | 响应中允许返回的最大数据量(字节),仅支持Kafka大于等于0.10.1.0 | 10485760(10MB) |
| maxWaitTimeInMS | 如果服务器未立即积累到足够数据以满足minBytes,则最多等待的时间(毫秒) | 5000 |
| retry | 重试设置,可查看retry配置项获取更多信息 | {retries: 5} |
| readUncommitted | 配置消费者的脱离级别,如果为false默认,消费者不会读取未提交的事务消息 | false |
| maxInFlightRequests | 同时允许进行的最大请求数,如果为假值(如null),则表示无限制 | null(无限制) |
| rackId | 配置消费者所在的机架 rack,以启用副本读取(Follower Fetching)功能 | null(总是从Leader读取) |
KafkaJS的消费者(Consumer)提供了pause和resume方法,用于暂停和恢复一个或多个主题中消费消息。
此外,还提供了paused方法,用于获取当前所有已暂停的主题列表。
消费者可以通过 pause 与 resume 方法来暂停或恢复对一个或多个主题的消费消息。还可以通过 paused() 方法获取当前被暂停的主题列表。
注意:当某个主题被暂停后,它在下一格轮询周期中将不会被拉取,其当前批次内的后续消息也不会传递给 eachMessage 处理函数。
调用 puase() 时如果指定的主题并未被该消费者订阅,则不会执行任何操作(no-op)。同样地,如果调用 resume() 的主题并未处于暂停状态,也不会有任何效果。
注意:如果消费者当前未运行(即未执行run),调用 pause() 或 resume() 会抛出错误。
一个常见的应用场景是,当消费者依赖的外部系统(例如数据库或HTTP API)压力过大时,我们希望暂时暂停消息消费,待一段时间后再恢复。
const consumer = kafka.consumer({ groupId: 'test-group' });
await consumer.connect();
await consumer.subscribe({ topics: ['jobs'] });
await consumer.run({
eachMessage: async ({ topic, partition, message }) => {
try {
await sendToDependency(message);
} catch (error) {
if (e instanceof TooManyRequestsError) {
// 暂停当前主题的消费者
consumer.pause([{ topic }]);
// 等待指定事件后再恢复
setTimeout(() => consumer.resume([{ topic }]), e.retryAfter * 1000);
}
throw e
}
}
});如果希望实现更细粒度的控制,也可以只暂停特定主题的某个分区,而不是整个主题,这种“按分区暂停”的能力让我们能够隔离处理较慢的分区,而其他分区仍可正常消费。
consumer.run({
partitionsConsumedConcurrently: 3, // 默认值为 1
eachMessage: async ({ topic, partition, message }) => {
try {
await sendToDependency(message)
} catch (e) {
if (e instanceof TooManyRequestsError) {
consumer.pause([{ topic, partitions: [partition] }])
// 其他分区仍会继续拉取与处理
setTimeout(() => {
consumer.resume([{ topic, partitions: [partition] }])
// 其他已暂停的分区不会被自动恢复
}, e.retryAfter * 1000)
}
throw e
}
},
})KafkaJS为 eachMessage 回调提供了一个 pause() 方法,允许你快速暂停当前正在处理的主题分区,无需手动传入 topic 和 partition。
await consumer.connect()
await consumer.subscribe({ topics: ['jobs'] })
await consumer.run({
eachMessage: async ({ topic, message, pause }) => {
try {
await sendToDependency(message)
} catch (e) {
if (e instanceof TooManyRequestsError) {
const resumeThisPartition = pause()
// 仅暂停当前分区,其他分区仍继续运行
setTimeout(resumeThisPartition, e.retryAfter * 1000)
}
throw e
}
},
})可以使用 consumer.paused() 方法查看所有被暂停的主题及其分区:
const pausedTopicPartitions = consumer.paused()
for (const topicPartitions of pausedTopicPartitions) {
const { topic, partitions } = topicPartitions
console.log({ topic, partitions })
}输出示例
{ topic: 'jobs', partitions: [0, 2] }kafkaJS的消费者提供了 seek 方法,用于手动移动某个主题分区(topic/partition)中的偏移量(offset)。
该方法必须在消费者初始化并运行后(即执行 consumer.run() 之后)调用。
const consumer = kafka.consumer({ groupId: 'test-group' });
await consumer.connect();
await consumer.subscribe({ topics: ['test-topic'] });
// 不需要等待 consumer.run 完成
consumer.run({ eachMessage: async ({ topic, message }) => true });
// 手动指定offset位置
consumer.seek({ topic: 'test-topic', partition: 0, offset: '10' });当你使用 seek() 调整到指定offset时,当前正在处理的批次中的消息将会被标记为 过期(stale)并被丢弃,这保证了消费者下次从该分区读取消息时,会从 seek指定的offset开始。
如果你使用 eachBatch 接口(批量消费),请务必在处理消费前调用 isStale() 检查该批次是否仍然有效。
控制是否自动提交autoCommit
默认情况下,消费者在执行 seek() 后会自动提交新偏移量。如果你不希望立即提交 offset,可以将消费者的 autoCommit 选项设置为 false。
consumer.run({
autoCommit: false, // 禁止自动提交
eachMessage: async ({ topic, message }) => true
})
// 这时执行 seek 只会定位偏移量,不会提交 offset
consumer.seek({ topic: 'example', partition: 0, offset: "12384" })
// 如果要提交仍旧要用 commitOffsets
// await consumer.commitOffsets([
// {
// topic,
// partition,
// offset: (Number(NewOffset).toString())
// }
// ]);可以配置 消费者组中分区的分配策略,KafkaJS默认使用 轮询分配器(round robin assigner)
一个 分区分配器(partition assigner)是一个函数,它返回一个具有以下接口的对象。
const MyPartitionAssigner = ({ cluster }) => ({
name: 'MyPartitionAssigner',
version: 1,
async assign({ members, topics }) {},
protocol({ topics }) {}
})assign() 方法必须返回一个分区分配计划(assignment plan),该计划指定了每个主题的分区如何分配给消费者成员。
一个分配计划包含:
成员分配(memberAssugnment)必须经过编码,可使用kafkaJS提供的MemberAssignment工具完成。
const { AssignerProtocol: { MemberAssignment } } = require('kafkajs')
const MyPartitionAssigner = ({ cluster }) => ({
version: 1,
async assign({ members, topics }) {
// 执行自定义分配逻辑
return myCustomAssignmentArray.map(memberId => ({
memberId,
memberAssignment: MemberAssignment.encode({
version: this.version,
assignment: assignment[memberId],
})
}))
}
})protocol()方法必须返回:
元数据同样需要编码,可使用 MemberMetadata 工具完成。
const { AssignerProtocol: { MemberMetadata } } = require('kafkajs')
const MyPartitionAssigner = ({ cluster }) => ({
name: 'MyPartitionAssigner',
version: 1,
protocol({ topics }) {
return {
name: this.name,
metadata: MemberMetadata.encode({
version: this.version,
topics,
}),
}
}
})你的 protocol() 方法大概率会与上面的示例类似,但KafkaJS默认并不自动实现它们,因为你可能希望在协议的userData中包含额外数据。如果需要了解更多,请参考 MemberMetadata#encode 的实现。
当你编写好自定义分配器后,需要将它添加到消费者的 partitionAssigners 列表中。
务必保留默认的 roundRobin 分配器,这样旧的消费者在部署时仍能与新的消费者保持兼容。
const { PartitionAssigners: { roundRobin } } = require('kafkajs')
kafka.consumer({
groupId: 'my-group',
partitionAssigners: [
MyPartitionAssigner,
roundRobin
]
})const { AssignerProtocol: { MemberAssignment, MemberMetadata } } = require('kafkajs')
const MyPartitionAssigner = ({ cluster }) => ({
name: 'MyPartitionAssigner',
version: 1,
async assign({ members, topics }) {
// 假设我们只处理单个 topic
const topic = topics[0].topic
const partitions = topics[0].partitions
// 简单分配:按索引轮流分配
const assignment = {}
members.forEach((member, index) => {
assignment[member.memberId] = {
[topic]: partitions.filter((_, i) => i % members.length === index)
}
})
return members.map(member => ({
memberId: member.memberId,
memberAssignment: MemberAssignment.encode({
version: this.version,
assignment: assignment[member.memberId]
})
}))
},
protocol({ topics }) {
return {
name: this.name,
metadata: MemberMetadata.encode({
version: this.version,
topics
})
}
}
})在Kafka的消费者组(Consumer Group)机制中,分区分配(Partition Assignment)逻辑是由消费者客户端之间协调完成的,而不是由Broker主动决定的。
分区分配的主导者是谁?
当你使用 kafkajs 或官方Java客户端时,每个消费者属于某个 consumer group,在这个group中,Kafka会选出一个 Group Coordinator(组协调者 是一台Broker)。 “组协调者 Group Coordinator”是一个特殊角色的Broker,但它不直接决定分区分配逻辑,而是只负责协调流程(即组织谁去做分配、提交结果)。
实际分配逻辑由谁执行?
分区分配由 消费者客户端 自己完成,步骤如下:
Describe Group 描述消费者组
实验性功能,此功能可能在未来的KafkaJS版本中被修改或移除。
此方法用于返回当前配置的消费者组的元数据。
const data = await consumer.describeGroup()
// {
// errorCode: 0,
// groupId: 'consumer-group-id-f104efb0e1044702e5f6',
// members: [
// {
// clientHost: '/172.19.0.1',
// clientId: 'test-3e93246fe1f4efa7380a',
// memberAssignment: Buffer,
// memberId: 'test-3e93246fe1f4efa7380a-ff87d06d-5c87-49b8-a1f1-c4f8e3ffe7eb',
// memberMetadata: Buffer,
// },
// ],
// protocol: 'RoundRobinAssigner',
// protocolType: 'consumer',
// state: 'Stable',
// }KafkaJS原生仅支持GZIP压缩算法。
但也可以通过额外扩展支持其他压缩编解码器。
KafkaJS支持一种称为 “Follower Fetching 从副本拉取” 的机制。
在这种模式下,消费者会优先尝试从自己处于相同机架 rack中的broker拉取数据,而不是总是从leader节点读取。
这种方式的好处:
这里的 rack 机架,概念非常灵活,可以表示
管理客户端托管所有集群操作,例如 createTopics,createPartitions 等等。
const { Kafka } = require('kafkajs');
const kafka = new Kafka({
clientId: 'my-app',// 客户端ID
// Kafka集群地址,把Broker的地址写到数组内,每个item为一个Broker
brokers: ['127.0.0.1:29092']
});
// 创建admin实例
(async () => {
const admin = kafka.admin();
await admin.connect();
const topics = await admin.listTopics();
console.log("已有的Topic: ", topics);
await admin.disconnect();
})();listTopics 列出所有现有主题的名称,并返回一个字符串数组。如果出现错误,该方法将抛出异常。
const topics = await admin.listTopics();
// [ 'test-topic', '__transaction_state', '__consumer_offsets' ]createTopics 该方法会判断 true 主题是否创建成功或false是否已存在,如果出现错误,该方法会抛出异常。
admin.createTopics(options: {
validateOnly?: boolean
waitForLeaders?: boolean
timeout?: number
topics: ITopicConfig[]
}): Promise<boolean>
export interface ITopicConfig {
topic: string
numPartitions?: number // default: -1 (uses broker `num.partitions` configuration)
replicationFactor?: number // default: -1 (uses broker `default.replication.factor` configuration)
replicaAssignment?: ReplicaAssignment[] // Example: [{ partition: 0, replicas: [0,1,2] }] - default: []
configEntries?: IResourceConfigEntry[] // Example: [{ name: 'cleanup.policy', value: 'compact' }] - default: []
}| 属性 | 描述 | 默认值 |
|---|---|---|
| topics | 主题定义 | |
| validateOnly | 如果满足此条件true,则请求将被验证,但主题不会被创建 | false |
| timeout | 等待主题在控制器节点上完全创建所需的时间(以毫秒为单位) | 5000 |
| waitForLeaders | 如果是true它将等待直到新主题的元数据不再抛出异常 LEADER_NOT_AVAILABLE | true |
await admin.deleteTopics({
topics: <String[]>,
timeout: <Number>, // default: 5000
})在 Apache Kafka版本 1.0.0之前,主题删除功能默认处于禁用状态,要启用此功能,请设置服务器配置
delete.topic.enable=truecreatePartitions 成功时将解析,出错时,该方法将抛出异常。
await admin.createPartitions({
validateOnly: <boolean>,
timeout: <Number>,
topicPartitions: <TopicPartition[]>,
})
TopicPartition结构:
{
topic: <String>,
count: <Number>, // partition count
assignments: <Array<Array<Number>>> // Example: [[0,1],[1,2],[2,0]]
}| 属性 | 描述 | 默认值 |
|---|---|---|
| topicPartitions | 主题分区定义 | |
| validateOnly | 如果满足此条件true,则请求将被验证,但主题不会被创建 | false |
| timeout | 等待主题在控制器节点上完全被创建所需的时间(以毫秒为单位) | 5000 |
| count | 新增分区数量,必填 | |
| assignments | 为每个新分区分配的Broker | null |
await admin.fetchTopicMetadata({ topics: <Array<String>> })TopicsMetadata结构
{
topics: <Array<TopicMetadata>>,
}TopicMetadata结构:
{
name: <String>,
partitions: <Array<PartitionMetadata>> // default: 1
}PartitionMetadata结构
{
partitionErrorCode: <Number>, // default: 0
partitionId: <Number>,
leader: <Number>,
replicas: <Array<Number>>,
isr: <Array<Number>>,
}如果提供的任何Topic尚不存在,管理客户端将抛出异常。
如果省略该topics参数,管理客户端将获取所有Topic的元数据
await admin.fetchTopicMetadata()fetchTopicOffsets 返回主题的最新偏移量
await admin.fetchTopicOffsets(topic)
// [
// { partition: 0, offset: '31004', high: '31004', low: '421' },
// { partition: 1, offset: '54312', high: '54312', low: '3102' },
// { partition: 2, offset: '32103', high: '32103', low: '518' },
// { partition: 3, offset: '28', high: '28', low: '0' },
// ]指定一个 timestamp 偏移量,以获取每个分区上消息时间戳 大于或等于 给定时间戳的最早偏移量
// fetchTopicOffsetsByTimestamp(topic: string, timestamp?: number): Promise<Array<SeekEntry>>
await admin.fetchTopicOffsetsByTimestamp(topic, timestamp)
// [
// { partition: 0, offset: '3244' },
// { partition: 1, offset: '3113' },
// ]fetchOffsets 返回主题列表的消费者组偏移量
admin.fetchOffsets({ groupId: 'test-group', topics: ['test-topic'] }).then(result => {
console.log('group offsets:', JSON.stringify(result));
});
// group offsets: [{"topic":"test-topic","partitions":[{"partition":0,"offset":"157","metadata":null},{"partition":1,"offset":"157","metadata":null}]}]如果你想获取某个消费者组在所有主题 topics 上的已提交偏移量(committed offsets),可以省略 topics 参数。
你还可以包含一个可选参数 resolveOffsets,用于在不启动消费者的情况下解析(resolve)偏移量,这在调用 resetOffsets 之后直接获取偏移量时非常有用。
resolveOffsets这个参数控制了KafkaJS是否去“解析” offset值成实际数值。
await admin.resetOffsets({ groupId, topic })
await admin.fetchOffsets({ groupId, topics: [topic], resolveOffsets: false })
// [
// { partition: 0, offset: '-1' },
// { partition: 1, offset: '-1' },
// { partition: 2, offset: '-1' },
// { partition: 3, offset: '-1' },
// ]含义:
也就是,此时只是“逻辑上”充值了offset,但KafkaJS还没去查真正该从哪里开始读,其实也就是本地判断的。
resolveOffsets为true,会和Kafka集群交互解析offset,得到实际数值。
await admin.resetOffsets({ groupId, topic })
await admin.fetchOffsets({ groupId, topics: [topic], resolveOffsets: true })
// [
// { partition: 0, offset: '31004' },
// { partition: 1, offset: '54312' },
// { partition: 2, offset: '32103' },
// { partition: 3, offset: '28' },
// ]含义:
| 操作 | 行为 | 是否立即得到实际 offset |
|---|---|---|
resetOffsets() |
通知 Kafka 重置 offset | ❌ 否,只记录重置信息 |
fetchOffsets({ resolveOffsets: false }) |
读取元数据中保存的 offset | ❌ 得到 -1 或旧值 |
fetchOffsets({ resolveOffsets: true }) |
去 broker 查询实际的 earliest/latest 数字 | ✅ 得到真实 offset 数值 |
resetOffsets 将消费者组的偏移量重置为最早或最新的偏移量(默认为最新偏移量)。执行重置时,消费者组必须没有任何正在运行的实例,否则,该命令将被拒绝。
await admin.resetOffsets({ groupId, topic }) // latest by default
// await admin.resetOffsets({ groupId, topic, earliest: true })setOffsets 允许您将消费者组偏移量设置为任何值
await admin.setOffsets({
groupId: <String>,
topic: <String>,
partitions: <SeekEntry[]>,
})SeekEntry结构
{
partition: <Number>,
offset: <String>,
}例子
await admin.setOffsets({
groupId: 'my-consumer-group',
topic: 'custom-topic',
partitions: [
{ partition: 0, offset: '35' },
{ partition: 3, offset: '19' },
]
})组合操作 fetchTopicOffsetsByTimestamp 可以 setOffsets 将消费者组在每个分区上的偏移量重置为时间戳大于或等于给定时间戳的最早偏移量,执行重置时,消费者组必须没有正在运行的实例,否则,该命令将被拒绝。
await admin.setOffsets({ groupId, topic, partitions: await admin.fetchTopicOffsetsByTimestamp(topic, timestamp) })允许您获取有关代理集群的信息,这主要用于监控或运维,通常与典型的事件处理无关。
await admin.describeCluster()
// {
// "brokers": [
// {
// "nodeId": 2,
// "host": "127.0.0.1",
// "port": 29092
// }
// ],
// "controller": 2,
// "clusterId": "5L6g3nShT-eMCtK--X86sw"
// }获取指定resource的配置信息
await admin.describeConfigs({
includeSynonyms: <boolean>,
resources: <ResourceConfigQuery[]>
})ResourceConfigQuery结构
{
type: <ConfigResourceType>,
name: <String>,
configNames: <String[]>
}返回给定资源的所有配置
let describeConfigResponse = await admin.describeConfigs({
includeSynonyms: false,
resources: [
{
type: ConfigResourceTypes.TOPIC,
name: 'test-topic'
}
]
});返回给定资源的特定配置
const { ConfigResourceTypes } = require('kafkajs')
await admin.describeConfigs({
includeSynonyms: false,
resources: [
{
type: ConfigResourceTypes.TOPIC,
name: 'topic-name',
configNames: ['cleanup.policy']
}
]
});
// ConfigResourceTypes
// UNKNOWN: 0,
// TOPIC: 2,
// BROKER: 4,
// BROKER_LOGGER: 8,示例回复
{
resources: [
{
configEntries: [{
configName: 'cleanup.policy',
configValue: 'delete',
isDefault: true,
configSource: 5,
isSensitive: false,
readOnly: false
}],
errorCode: 0,
errorMessage: null,
resourceName: 'topic-name',
resourceType: 2
}
],
throttleTime: 0
}更新指定资源的配置。
await admin.alterConfigs({
validateOnly: false,
resources: <ResourceConfig[]>
})ResourceConfig结构
{
type: <ConfigResourceType>,
name: <String>,
configEntries: <ResourceConfigEntry[]>
}ResourceConfigEntry结构
{
name: <String>,
value: <String>
}例子
const { ConfigResourceTypes } = require('kafkajs')
await admin.alterConfigs({
resources: [{
type: ConfigResourceTypes.TOPIC,
name: 'topic-name',
configEntries: [{ name: 'cleanup.policy', value: 'compact' }]
}]
})示例回复
{
resources: [{
errorCode: 0,
errorMessage: null,
resourceName: 'topic-name',
resourceType: 2,
}],
throttleTime: 0,
}列出Broker提供的分组
console.log(await admin.listGroups());
// { groups: [ { groupId: 'test-group', protocolType: 'consumer' } ] }通过指定 groupIds 来描述(查看)消费者组的信息。
这个方法与 consumer.describeGroup() 类似但不同的是:
await admin.describeGroups(['testgroup'])返回结果示例
{
groups: [
{
errorCode: 0,
groupId: 'testgroup',
members: [
{
clientHost: '/172.19.0.1',
clientId: 'test-3e93246fe1f4efa7380a',
memberAssignment: Buffer,
memberId: 'test-3e93246fe1f4efa7380a-ff87d06d-5c87-49b8-a1f1-c4f8e3ffe7eb',
memberMetadata: Buffer,
},
],
protocol: 'RoundRobinAssigner',
protocolType: 'consumer',
state: 'Stable',
},
],
}辅助解码函数(Helper function)
KafkaJS提供了一个工具类 AssignerProtocol
用于解码消费者组成员的二进制信息,即上面结果里的 memberMetadata、memberAssignment
const memberMetadata = AssignerProtocol.MemberMetadata.decode(memberMetadata)
const memberAssignment = AssignerProtocol.MemberAssignment.decode(memberAssignment)按以下方式删除组 groupId
请注意,您只能删除没有消费者连接的组。
await admin.deleteGroups([groupId])例子:
await admin.deleteGroups(['group-test'])示例回复:
[
{groupId: 'testgroup', errorCode: 'consumer'}
]由于此方法接受多个 groupId 参数,因此可能无法删除一个或多个提供的组,如果删除失败,它将抛出一个包含失败组的错误。
try {
await admin.deleteGroups(['a', 'b', 'c'])
} catch (error) {
// error.name 'KafkaJSDeleteGroupsError'
// error.groups = [{
// groupId: a
// error: KafkaJSProtocolError
// }]
}删除所选主题的记录。这将删除给定分区中从最早偏移量到指定目标偏移量(不包括目标偏移量)的所有记录。要删除 分区中的所有记录,请使用目标偏移量-1。
请注意,您不能删除任意范围内的记录(它始终会从最早可用的偏移量开始删除)。
await admin.deleteTopicRecords({
topic: <String>,
partitions: <SeekEntry[]>,
})例子
await admin.deleteTopicRecords({
topic: 'custom-topic',
partitions: [
{ partition: 0, offset: '30' }, // delete up to and including offset 29
{ partition: 3, offset: '-1' }, // delete all available records on this partition
]
})admin.createAcls
| 名称 | 含义 |
|---|---|
| AclResourceTypes | 资源类型,比如
TOPIC、GROUP、CLUSTER、TRANSACTIONAL_ID
等 |
| AclOperationTypes | 操作类型,比如
READ、WRITE、DELETE、ALL
等 |
| AclPermissionTypes | 权限类型,ALLOW(允许)或
DENY(拒绝) |
| ResourcePatternTypes | 资源名称匹配方式,LITERAL(精确匹配)或
PREFIXED(前缀匹配) |
const {
AclResourceTypes,
AclOperationTypes,
AclPermissionTypes,
ResourcePatternTypes,
} = require('kafkajs')
const acl = [
{
resourceType: AclResourceTypes.TOPIC,
resourceName: 'topic-name',
resourcePatternType: ResourcePatternTypes.LITERAL,
principal: 'User:bob',
host: '*',
operation: AclOperationTypes.ALL,
permissionType: AclPermissionTypes.DENY,
},
{
resourceType: AclResourceTypes.TOPIC,
resourceName: 'topic-name',
resourcePatternType: ResourcePatternTypes.LITERAL,
principal: 'User:alice',
host: '*',
operation: AclOperationTypes.ALL,
permissionType: AclPermissionTypes.ALLOW,
},
]
await admin.createAcls({ acl })请注意,您的集群中的安全功能可能已被禁用。在这种情况下,操作将抛出错误。
KafkaJSProtocolError: Security features are disabled上面定义了两条ACL规则
规则1,意思是禁止用户bob对topic-name的任何操作。
| 字段 | 说明 |
|---|---|
| resourceType | 对象是一个主题 Topic |
| resourceName | 具体的topic名称为topic-name |
| resourcePatternType | 精确匹配(不是前缀匹配) |
| principal | Kafka用户User:bob |
| host | *表示来自任何主机 |
| operation | ALL 代表所有操作,如读写删除等 |
| permissionType | DENY 拒绝所有权限 |
规则2,意思是允许用户alice对topic-name执行所有操作
| 字段 | 说明 |
|---|---|
| principal | Kafka 用户 User:alice |
| permissionType | ALLOW |
admin.deleteAcls
const {
AclResourceTypes,
AclOperationTypes,
AclPermissionTypes,
ResourcePatternTypes,
} = require('kafkajs')
const acl = {
resourceName: 'topic-name,
resourceType: AclResourceTypes.TOPIC,
host: '*',
permissionType: AclPermissionTypes.ALLOW,
operation: AclOperationTypes.ANY,
resourcePatternType: ResourcePatternTypes.LITERAL,
}
await admin.deleteAcls({ filters: [acl] })
// {
// filterResponses: [
// {
// errorCode: 0,
// errorMessage: null,
// matchingAcls: [
// {
// errorCode: 0,
// errorMessage: null,
// resourceType: AclResourceTypes.TOPIC,
// resourceName: 'topic-name',
// resourcePatternType: ResourcePatternTypes.LITERAL,
// principal: 'User:alice',
// host: '*',
// operation: AclOperationTypes.ALL,
// permissionType: AclPermissionTypes.ALLOW,
// },
// ],
// },
// ],
// }请注意,您的集群中的安全功能可能已被禁用。在这种情况下,操作将抛出错误。
KafkaJSProtocolError: Security features are disabledadmin.describeAcls
const {
AclResourceTypes,
AclOperationTypes,
AclPermissionTypes,
ResourcePatternTypes,
} = require('kafkajs')
await admin.describeAcls({
resourceName: 'topic-name,
resourceType: AclResourceTypes.TOPIC,
host: '*',
permissionType: AclPermissionTypes.ALLOW,
operation: AclOperationTypes.ANY,
resourcePatternTypeFilter: ResourcePatternTypes.LITERAL,
})
// {
// resources: [
// {
// resourceType: AclResourceTypes.TOPIC,
// resourceName: 'topic-name,
// resourcePatternType: ResourcePatternTypes.LITERAL,
// acls: [
// {
// principal: 'User:alice',
// host: '*',
// operation: AclOperationTypes.ALL,
// permissionType: AclPermissionTypes.ALLOW,
// },
// ],
// },
// ],
// }请注意,您的集群中的安全功能可能已被禁用。在这种情况下,操作将抛出错误。
KafkaJSProtocolError: Security features are disabled此方法用于重新分配分区所在的副本。如果出现错误,此方法将抛出异常。
await admin.alterPartitionReassignments({
topics: <PartitionReassignment[]>,
timeout: <Number> // optional - 5000 default
})
// PartitionReassignment Structure:
{
topic: <String>,
partitionAssignment: <Number[]> // Example: [{ partition: 0, replicas: [0,1,2] }]
}在Kafka里,一个Topic会被分成多个分区(partition)。每个分区又会被复制(replicate)到多个broker(Kafka节点)上,用来保证高可用。
举个例子:
| Topic | Partition | Replicas(副本在哪些 broker 上) |
|---|---|---|
user-events |
0 | [0, 1, 2] |
user-events |
1 | [1, 2, 3] |
user-events |
2 | [2, 3, 0] |
也就是说:
为什么需要 alter Partition Reassignments
有时候,我们希望调整副本分布,比如
这些时候,就可以手动指定新的副本方案。
admin.alterPartitionReassignments()| 项目 | 说明 |
|---|---|
| ⚙️ 权限 | 需要管理员权限 |
| 📦 副本必须存在于 broker 列表中 | [1,3,4] 中的编号必须是已存在的 broker ID |
| ⏳ 迁移期间 | Kafka 会自动复制数据,可能会导致额外网络和磁盘负载 |
| 🔍 可搭配使用 | describePartitionReassignments() 可查看迁移进度 |
| 🚫 错误情况 | 如果 broker ID 不存在或重复,会抛出异常 |
此方法用于列出当前正在进行的分区重新分配操作,如果发生错误,此方法将抛出异常;如果成功,则返回ListPartitionReassignmentsResponse 对象。如果请求的分区不存在,则不会将其包含在响应中。
await admin.listPartitionReassignments({
topics: <TopicPartitions[]>, // optional, if null then all topics will be returned.
timeout: <Number> // optional - 5000 default
})
// TopicPartitions结构
{
topic: <String>,
partitions: <Array>
}生成的 ListPartitionReassignmentsResponse 结构:
{
topics: <OngoingTopicReassignment[]>
}
// OngoingTopicReassignment 结构
{
topic: <String>,
partitions: <OngoingPartitionReassignment[]>
}
// OngoingPartitionReassignment结构
{
// 分区编号(即该主题下的第几个分区,从 0 开始)
partitionIndex: <Number>,
// 当前该分区的副本集合(正在使用的 broker ID 列表)
replicas: <Number[]>,
// 正在添加的新副本(broker ID 列表)
// 当分区被重新分配时,这些 broker 会从旧副本同步数据
addingReplicas: <Number[]>,
// 正在移除的旧副本(broker ID 列表)
// 当迁移完成后,这些 broker 将不再保存该分区副本
removingReplicas: <Number[]>
}注意:如果分区没有进行重新分配,则其 AddingReplicas 和 RemovingReplicas 字段将为空。
KafkaJS 监控事件(Instrumentation Events)
KafkaJS 的某些操作内置了事件监控机制,通过 EventEmitter 实现。
你可以使用 consumer.on()、producer.on()、admin.on() 方法来监听这些事件。
const { HEARTBEAT } = consumer.events
const removeListener = consumer.on(HEARTBEAT, e =>
console.log(`heartbeat at ${e.timestamp}`)
)
// 取消监听
removeListener()说明:
事件结构(Instrumentation Event),每个事件对象的结构如下:
{
id: <Number>, // 事件 ID(唯一标识)
type: <String>, // 事件类型名,如 'HEARTBEAT'、'REQUEST' 等
timestamp: <Number>, // 时间戳(毫秒)
payload: <Object> // 事件附带的数据
}| 事件 | payload(负载内容) | 描述 |
|---|---|---|
| REQUEST | {broker, clientId, correlationId, size, createdAt, sentAt, pendingDuration, duration, apiName, apiKey, apiVersion} |
每次向 broker 发送网络请求时触发 |
| CONNECT | 无 | 消费者成功连接到 broker 时触发 |
| GROUP_JOIN | {groupId, memberId, leaderId, isLeader, memberAssignment, groupProtocol, duration} |
消费者加入消费组时触发 |
| FETCH_START | {} |
开始从 broker 拉取消息时触发 |
| FETCH | {numberOfBatches, duration} |
拉取消息完成时触发 |
| START_BATCH_PROCESS | {topic, partition, highWatermark, offsetLag, offsetLagLow, batchSize, firstOffset, lastOffset} |
用户开始处理一个消息批次时触发 |
| END_BATCH_PROCESS | {topic, partition, highWatermark, offsetLag, offsetLagLow, batchSize, firstOffset, lastOffset, duration} |
用户处理一个批次完成时触发(包括 eachMessage/eachBatch 的执行) |
| COMMIT_OFFSETS | {groupId, memberId, groupGenerationId, topics} |
成功提交偏移量时触发 |
| STOP | 无 | 消费者停止时触发 |
| DISCONNECT | 无 | 消费者断开连接时触发 |
| CRASH | {error, groupId, restart} |
消费者崩溃时触发。若错误可重试,KafkaJS
会尝试重启消费者;若错误不可重试,则消费者会停止并退出。 若你的应用希望对崩溃作出反应(如清理资源、重新启动消费者或退出进程),应监听此事件。 |
| HEARTBEAT | {groupId, memberId, groupGenerationId} |
向协调器发送心跳包时触发 |
| REBALANCING | {groupId, memberId} |
消费者组开始重新平衡时触发 |
| REQUEST_TIMEOUT | {broker, clientId, correlationId, createdAt, sentAt, pendingDuration, apiName, apiKey, apiVersion} |
请求 broker 超时时触发 |
| REQUEST_QUEUE_SIZE | {broker, clientId, queueSize} |
每当请求队列长度发生变化时触发(用于监控并发请求数) |
| RECEIVED_UNSUBSCRIBED_TOPICS | {groupId, generationId, memberId, assignedTopics, topicsSubscribed, topicsNotSubscribed} |
当消费组中部分成员订阅的主题集合不一致时触发 |
| 事件 | payload(负载内容) | 描述 |
|---|---|---|
| REQUEST | {broker, clientId, correlationId, size, createdAt, sentAt, pendingDuration, duration, apiName, apiKey, apiVersion} |
每次向 broker 发送请求时触发 |
| CONNECT | 无 | 生产者成功连接到 broker 时触发 |
| DISCONNECT | 无 | 生产者断开连接时触发 |
| REQUEST_TIMEOUT | {broker, clientId, correlationId, createdAt, sentAt, pendingDuration, apiName, apiKey, apiVersion} |
请求超时时触发 |
| REQUEST_QUEUE_SIZE | {broker, clientId, queueSize} |
请求队列大小变化时触发 |
| 事件 | payload(负载内容) | 描述 |
|---|---|---|
| REQUEST | {broker, clientId, correlationId, size, createdAt, sentAt, pendingDuration, duration, apiName, apiKey, apiVersion} |
每次向 broker 发送管理请求时触发 |
| CONNECT | 无 | Admin 客户端连接成功时触发 |
| DISCONNECT | 无 | Admin 客户端断开连接时触发 |
| REQUEST_TIMEOUT | {broker, clientId, correlationId, createdAt, sentAt, pendingDuration, apiName, apiKey, apiVersion} |
管理请求超时时触发 |
| REQUEST_QUEUE_SIZE | {broker, clientId, queueSize} |
请求队列大小变化时触发 |
自定义日志系统(Custom Logger)
KafkaJS 允许你使用 自定义日志系统 来替换默认的控制台日志输出。
通过 log creator(日志创建器) 实现,你可以将日志输出到第三方系统(如 winston、pino、log4js 等)。
什么是Log Creator?
一个log creator是一个函数:
日志处理函数在KafkaJS生成日志时被调用,并接受如下参数
({ namespace, level, label, log })| 参数 | 说明 |
|---|---|
| namespace | 产生日志的组件,例如
"connection"、"consumer"、"producer" |
| level | 日志级别(数值类型) |
| label | 日志级别的字符串形式,例如 "INFO" |
| log | 日志对象,包含时间戳、模块名、消息内容和附加数据 |
log对象结构
{
level: 4,
label: 'INFO', // 可取值: NOTHING, ERROR, WARN, INFO, DEBUG
timestamp: '2017-12-29T13:39:54.575Z',
logger: 'kafkajs',
message: 'Started',
// ... 其他用户自定义字段
}例如:logger.info('test', {extra_data: true}),这里
extra_data 就会出现在log对象中。
日志函数的一般结构
const MyLogCreator = logLevel => ({ namespace, level, label, log }) => {
// 示例:
// const { timestamp, logger, message, ...others } = log
// console.log(`${label} [${namespace}] ${message} ${JSON.stringify(others)}`)
}解释:
使用Winston实现自定义日志,下面使用Winston(常用Node.js日志库)集成的示例:
const { logLevel } = require('kafkajs')
const winston = require('winston')
// 将 KafkaJS 的日志级别映射到 Winston 的级别
const toWinstonLogLevel = level => {
switch(level) {
case logLevel.ERROR:
case logLevel.NOTHING:
return 'error'
case logLevel.WARN:
return 'warn'
case logLevel.INFO:
return 'info'
case logLevel.DEBUG:
return 'debug'
}
}
// 创建 Winston 日志器
const WinstonLogCreator = logLevel => {
const logger = winston.createLogger({
level: toWinstonLogLevel(logLevel),
transports: [
new winston.transports.Console(), // 输出到控制台
new winston.transports.File({ filename: 'myapp.log' }) // 输出到文件
]
})
// 返回 KafkaJS 日志回调函数
return ({ namespace, level, label, log }) => {
const { message, ...extra } = log
logger.log({
level: toWinstonLogLevel(level),
message,
extra,
})
}
}通过logCreator选项配置,将自定义Logger应用于Kafka客户端
const kafka = new Kafka({
clientId: 'my-app',
brokers: ['kafka1:9092', 'kafka2:9092'],
logLevel: logLevel.ERROR,
logCreator: WinstonLogCreator
})含义:
获取实例的命令日志器 Namespaced Logger
KafkaJS 的每个组件(client、consumer、producer、admin)都提供 logger() 方法,可在运行时直接输出带命名空间的日志。
const client = new Kafka(...)
client.logger().info('client started')
const consumer = kafka.consumer(...)
consumer.logger().info('consumer initialized')
const producer = kafka.producer(...)
producer.logger().info('producer ready')
const admin = kafka.admin(...)
admin.logger().info('admin connected')总结:
| 功能 | 说明 |
|---|---|
| logCreator | 定义自定义日志创建器 |
| namespace | 标识产生日志的 KafkaJS 组件 |
| logLevel | 控制日志输出级别(DEBUG/INFO/WARN/ERROR) |
| 支持第三方库 | 可以用 winston、pino、bunyan
等 |
| 可扩展性 | 支持输出到文件、远程服务、Elastic Stack 等 |
重试机制详解(Retry Mechanism Explained)

afkaJS 的重试机制使用指数级增长的随机函数(exponential backoff with jitter)。 也就是说,每次重试之间的等待时间会逐步增加,同时加入随机化以避免所有客户端同时重试造成“雪崩”效应。
以下是 KafkaJS Retry Mechanism(重试机制) 的详细中文翻译与讲解👇
🧮 重试时间计算公式
第 1 次重试(1st retry)
固定等待时间:initialRetryTime
毫秒,默认值:300ms
第 N 次重试(Nth retry)
使用以下公式计算:
Random(previousRetryTime * (1 - factor), previousRetryTime * (1 + factor)) * multiplier其中参数含义如下:
| 参数 | 含义 | 默认值 |
|---|---|---|
previousRetryTime |
上一次重试的等待时间 | — |
factor |
随机波动系数(±范围) | 0.2(即 ±20%) |
multiplier |
指数增长倍率 | 2 |
initialRetryTime |
初始重试时间 | 300ms |
📘 实际计算举例
N = 1
第一轮时
previousRetryTime = initialRetryTime = 300ms
代入公式:
Random(300 * (1 - 0.2), 300 * (1 + 0.2)) * 2
=> Random(240, 360) * 2
=> (480, 720) ms✅ 因此第一次重试的延迟在 480ms ~ 720ms 之间。
N = 2
假设上一轮 (N = 1) 的延迟落在 480ms ~ 720ms
范围内,则:
当 previousRetryTime = 480ms 时:
Random(480 * (1 - 0.2), 480 * (1 + 0.2)) * 2
=> Random(384, 576) * 2
=> (768, 1152) ms当 previousRetryTime = 720ms 时:
Random(720 * (1 - 0.2), 720 * (1 + 0.2)) * 2
=> Random(576, 864) * 2
=> (1152, 1728) ms✅ 因此第二次重试的延迟范围为 768ms ~ 1728ms。
🔄 以此类推
随着重试次数 N
增加,等待时间会按倍数增长,同时引入一定随机性(factor),
保证整体退避机制既稳定增长又避免同步冲击。
JavaScript
const ip = require('ip')
const { Kafka, CompressionTypes, logLevel } = require('kafkajs')
const host = process.env.HOST_IP || ip.address()
const kafka = new Kafka({
logLevel: logLevel.DEBUG,
brokers: [`${host}:9092`],
clientId: 'example-producer',
})
const topic = 'topic-test'
const producer = kafka.producer()
const getRandomNumber = () => Math.round(Math.random(10) * 1000)
const createMessage = num => ({
key: `key-${num}`,
value: `value-${num}-${new Date().toISOString()}`,
})
const sendMessage = () => {
return producer
.send({
topic,
compression: CompressionTypes.GZIP,
messages: Array(getRandomNumber())
.fill()
.map(_ => createMessage(getRandomNumber())),
})
.then(console.log)
.catch(e => console.error(`[example/producer] ${e.message}`, e))
}
const run = async () => {
await producer.connect()
setInterval(sendMessage, 3000)
}
run().catch(e => console.error(`[example/producer] ${e.message}`, e))
const errorTypes = ['unhandledRejection', 'uncaughtException']
const signalTraps = ['SIGTERM', 'SIGINT', 'SIGUSR2']
errorTypes.forEach(type => {
process.on(type, async () => {
try {
console.log(`process.on ${type}`)
await producer.disconnect()
process.exit(0)
} catch (_) {
process.exit(1)
}
})
})
signalTraps.forEach(type => {
process.once(type, async () => {
try {
await producer.disconnect()
} finally {
process.kill(process.pid, type)
}
})
})TypeScript
import { Kafka, Message, Producer, ProducerBatch, TopicMessages } from 'kafkajs'
interface CustomMessageFormat { a: string }
export default class ProducerFactory {
private producer: Producer
constructor() {
this.producer = this.createProducer()
}
public async start(): Promise<void> {
try {
await this.producer.connect()
} catch (error) {
console.log('Error connecting the producer: ', error)
}
}
public async shutdown(): Promise<void> {
await this.producer.disconnect()
}
public async sendBatch(messages: Array<CustomMessageFormat>): Promise<void> {
const kafkaMessages: Array<Message> = messages.map((message) => {
return {
value: JSON.stringify(message)
}
})
const topicMessages: TopicMessages = {
topic: 'producer-topic',
messages: kafkaMessages
}
const batch: ProducerBatch = {
topicMessages: [topicMessages]
}
await this.producer.sendBatch(batch)
}
private createProducer() : Producer {
const kafka = new Kafka({
clientId: 'producer-client',
brokers: ['localhost:9092'],
})
return kafka.producer()
}
}SSL & SASL Authentication, 见KafkaJS-Examples_Consumer
JavaScript
const ip = require('ip')
const { Kafka, logLevel } = require('kafkajs')
const host = process.env.HOST_IP || ip.address()
const kafka = new Kafka({
logLevel: logLevel.INFO,
brokers: [`${host}:9092`],
clientId: 'example-consumer',
})
const topic = 'topic-test'
const consumer = kafka.consumer({ groupId: 'test-group' })
const run = async () => {
await consumer.connect()
await consumer.subscribe({ topic, fromBeginning: true })
await consumer.run({
// eachBatch: async ({ batch }) => {
// console.log(batch)
// },
eachMessage: async ({ topic, partition, message }) => {
const prefix = `${topic}[${partition} | ${message.offset}] / ${message.timestamp}`
console.log(`- ${prefix} ${message.key}#${message.value}`)
},
})
}
run().catch(e => console.error(`[example/consumer] ${e.message}`, e))
const errorTypes = ['unhandledRejection', 'uncaughtException']
const signalTraps = ['SIGTERM', 'SIGINT', 'SIGUSR2']
errorTypes.forEach(type => {
process.on(type, async e => {
try {
console.log(`process.on ${type}`)
console.error(e)
await consumer.disconnect()
process.exit(0)
} catch (_) {
process.exit(1)
}
})
})
signalTraps.forEach(type => {
process.once(type, async () => {
try {
await consumer.disconnect()
} finally {
process.kill(process.pid, type)
}
})
})TypeScript
import { Consumer, ConsumerSubscribeTopics, EachBatchPayload, Kafka, EachMessagePayload } from 'kafkajs'
export default class ExampleConsumer {
private kafkaConsumer: Consumer
private messageProcessor: ExampleMessageProcessor
public constructor(messageProcessor: ExampleMessageProcessor) {
this.messageProcessor = messageProcessor
this.kafkaConsumer = this.createKafkaConsumer()
}
public async startConsumer(): Promise<void> {
const topic: ConsumerSubscribeTopics = {
topics: ['example-topic'],
fromBeginning: false
}
try {
await this.kafkaConsumer.connect()
await this.kafkaConsumer.subscribe(topic)
await this.kafkaConsumer.run({
eachMessage: async (messagePayload: EachMessagePayload) => {
const { topic, partition, message } = messagePayload
const prefix = `${topic}[${partition} | ${message.offset}] / ${message.timestamp}`
console.log(`- ${prefix} ${message.key}#${message.value}`)
}
})
} catch (error) {
console.log('Error: ', error)
}
}
public async startBatchConsumer(): Promise<void> {
const topic: ConsumerSubscribeTopics = {
topics: ['example-topic'],
fromBeginning: false
}
try {
await this.kafkaConsumer.connect()
await this.kafkaConsumer.subscribe(topic)
await this.kafkaConsumer.run({
eachBatch: async (eachBatchPayload: EachBatchPayload) => {
const { batch } = eachBatchPayload
for (const message of batch.messages) {
const prefix = `${batch.topic}[${batch.partition} | ${message.offset}] / ${message.timestamp}`
console.log(`- ${prefix} ${message.key}#${message.value}`)
}
}
})
} catch (error) {
console.log('Error: ', error)
}
}
public async shutdown(): Promise<void> {
await this.kafkaConsumer.disconnect()
}
private createKafkaConsumer(): Consumer {
const kafka = new Kafka({
clientId: 'client-id',
brokers: ['example.kafka.broker:9092']
})
const consumer = kafka.consumer({ groupId: 'consumer-group' })
return consumer
}
}🔐 SSL 与 SASL 认证
以下示例假设你已经拥有一个有效的 SSL 证书,并使用 SASL(简单认证与安全层)中的 SCRAM-SHA-256 机制进行身份验证。
KafkaJS 还支持其他多种 SASL 认证机制(详见 客户端配置 Client Configuration 一节)。
const ip = require('ip')
const { Kafka, logLevel } = require('../index')
const host = process.env.HOST_IP || ip.address()
const kafka = new Kafka({
logLevel: logLevel.INFO,
brokers: [`${host}:9094`],
clientId: 'example-consumer',
ssl: {
rejectUnauthorized: true
},
sasl: {
mechanism: 'scram-sha-256',
username: 'test',
password: 'testtest',
},
})
const topic = 'topic-test'
const consumer = kafka.consumer({ groupId: 'test-group' })
const run = async () => {
await consumer.connect()
await consumer.subscribe({ topic, fromBeginning: true })
await consumer.run({
// eachBatch: async ({ batch }) => {
// console.log(batch)
// },
eachMessage: async ({ topic, partition, message }) => {
const prefix = `${topic}[${partition} | ${message.offset}] / ${message.timestamp}`
console.log(`- ${prefix} ${message.key}#${message.value}`)
},
})
}
run().catch(e => console.error(`[example/consumer] ${e.message}`, e))
const errorTypes = ['unhandledRejection', 'uncaughtException']
const signalTraps = ['SIGTERM', 'SIGINT', 'SIGUSR2']
errorTypes.forEach(type => {
process.on(type, async e => {
try {
console.log(`process.on ${type}`)
console.error(e)
await consumer.disconnect()
process.exit(0)
} catch (_) {
process.exit(1)
}
})
})
signalTraps.forEach(type => {
process.once(type, async () => {
try {
await consumer.disconnect()
} finally {
process.kill(process.pid, type)
}
})
})## 操作 Operations
### Kafka基本操作 Basic Kafka Operations
### 添加和删除主题 Adding and removing topics
### 修改主题 Modifying topics
### 优雅关机 Graceful shutdown
### 平衡领导力 Balancing leadership
### 跨机架平衡副本 Balancing replicas across racks
### 集群间镜像数据 Mirroring data between clusters & Geo-replication
### 检查消费者位置 Checking consumer position
### 管理群组 Managing groups
### 管理消费者群体 Managing consumer groups
### 管理共享组 Managing share groups
### 扩展集群 Expanding your cluster
### 退役经纪人 Decommissioning brokers
### 增加复制因子 Increasing replication factor
### 限制数据迁移期间的带宽使用 Limiting bandwidth usage during data migration
### 设置配额 Setting quotas
### 数据中心 Datacenters
### 地理复制(跨集群数据镜像)Geo-Replication (Cross-Cluster Data Mirroring)
### 地理复制概述 Geo-Replication Overview
### 什么是复制流程 What Are Replication Flows
### 配置地理复制 Configuring Geo-Replication
### 启动地理复制 Starting Geo-Replication
### 停止地理复制 Stopping Geo-Replication
### 应用配置更改 Applying Configuration Changes
### 监控地理复制 Monitoring Geo-Replication
### 多租户 Multi-Tenancy
### 多租户概念 Multi-Tenancy Overview
### 创建用户空间(命名空间)Creating User Spaces (Namespaces) For Tenants With Topic Naming
### 配置主题 Configuring Topics: Data Retention And More
### 保护集群和主题 Securing Clusters and Topics: Authentication, Authorization, Encryption
### 隔离租户 Isolating Tenants: Quotas, Rate Limiting, Throttling
### 监控和计量 Monitoring and Metering
### 多租户和地理复制 Multi-Tenancy and Geo-Replication
### 多租户进一步考虑 Further considerations
### Java版本 Java Version
### 硬件和操作系统 Hardware and OS
### 操作系统OS
### 磁盘和文件系统Disks and Filesystem
### 应用程序与操作系统刷新管理 Application vs. OS Flush Management
### Linux刷新行为 Understanding Linux OS Flush Behavior
### 文件系统选择 Filesystem Selection
### 更换KRaft控制器磁盘 Replace KRaft Controller Disk
### 监控 Monitoring
### 使用JMX进行远程监控的安全 Security Considerations for Remote Monitoring using JMX
### 小组协调员监控 Group Coordinator Monitoring
### 分层存储监控 Tiered Storage Monitoring
### KRaft监控 KRaft Monitoring Metrics
### 选择器监控 Selector Monitoring
### 公共节点监控 Common Node Monitoring
### 生产者监控 Producer Monitoring
### 消费者监控 Consumer Monitoring
### 连接监控 Connect Monitoring
### 流监控 Streams Monitoring
### 监控其他内容 Others about monitoring
### KRaft
### KRaft配置 Configuration
### KRaft升级 Upgrade
### KRaft供应节点 Provisioning Nodes
### KRaft控制者成员资格变更 Controller membership changes
### KRaft调试 Debugging
### KRaft部署注意事项 Deploying Considerations
### ZooKeeper到KRaft的迁移 ZooKeeper to KRaft Migration
### 分层存储 Tiered Storage
### 分层存储概述 Tiered Storage Overview
### 分层存储配置 Configuration
### 分层存储快速启动示例 Quick Start Example
### 分层存储限制 Limitations
### 消费者再平衡协议 Consumer Rebalance Protocol
### 交易协议 Transaction Protocol
### 合格的Leader副本 Eligible Leader Replicas
## 安全 Security
### 安全概述 Security Overview
### 监听器配置 Listener Configuration
### 使用SSL进行加密和身份验证 Encryption and Authentication using SSL
### 使用SASL进行身份验证 Authentication using SASL
### 授权和ACL Authorization and ACLs
### 在正在运行的集群中整合安全功能 Incorporating Security Features in a Running Cluster
## Kafka Connect Kafka Connect
### 概述 Overview
### 用户指南 User Guide
### 运行Kafka Connect Running Kafka Connect
### 配置连接器 Configuring Connectors
### 变换 Transformations
### REST API REST API
### Connect中的错误报告 Error Reporting in Connect
### 恰好一次支持 Exactly-once support
### 插件发现 Plugin Discovery
### 连接器开发指南 Connector Development Guide
### 核心概念和API Core Concepts and APIs
### 开发简单的连接器 Developing a Simple Connector
### 动态输入输出流 Dynamic Input/Output Streams
### 配置验证 Configuration Validation
### 使用模式 Working with Schemas
### 管理 Administration
## Kafka Streams Kafka Streams
### 使用Streams应用程序 Play with a Streams Application
### 编写自己的Streams应用程序 Write your own Streams Applications
### 开发者手册 Developer Manual
### 核心概念 Core Concepts
### 架构 Architecture
### 升级指南 Upgrade Guide